These AMDP programming guidelines are a proposal for ABAP and SAP BW projects. They were originally written for the use case of AMDP transformation routines in SAP BW/4HANA. Feel free to copy, modify and use them in your own projects as long as this article is linked as the source.
Call by Reference - A Note on Usage
This document will be updated over time: It will be adapted to new technical developments, errors will be corrected and missing information will be added. Therefore, I recommend that you do not copy this document but link to it. This way you will always have the latest version. An interesting article on this topic was written by Jelena Perfiljeva: Are Your ABAP Guidelines Misguided?
Preface
Development guidelines have several goals. Among others:
- Good readability and maintainability of source code.
- Uniform source code
- Avoidance of error sources
- Avoidance of long runtime
These guidelines are not a substitute for sound training of developers. Conversely, they do not contain all possible pitfalls that one can stumble upon. And even with the strictest adherence to all guidelines, errors and unclean code can be written. It is the responsibility of every developer to ensure that their source code meets professional standards above and beyond these guidelines.
Unclean code is not ready
The point of these guidelines is to set minimum requirements for quality and consistency. They should be considered as part of the Definition of Done for AMDP transformation routines. This means that if these guidelines are not (yet) fully implemented, then the code is not ready and must not be transported. This also applies if the code already delivers the desired result.
Exceptions
Of course, there are situations in which you have to deviate from the guidelines for technical reasons. However, you should
- not decide alone, but always involve a competent colleague. Often you simply don't have the good ideas.
- also write explicitly in the code in a comment why it was done that way.
Readability of the code
No errors can hide in clean code. - They can occur, but are then easy to discover. The following applies accordingly:
Readability over optimisation - premature optimisation is the root of all evil
There is no doubt that the grail of efficiency leads to abuse. Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. (Donald E. Knuth, 1974 ! )
Well-structured and articulated SQLScript source code that respects the points described below can usually be optimised well and executed quickly by the database. Advance optimisation beyond the points mentioned below is not done. Before performance optimisations are made, a problem must actually exist and a thorough runtime analysis must have been carried out.
Naming
Some important points are listed below. A more extensive and detailed discussion of the topic, with many examples and good reasons, can be found in the book Clean Code by Robert C. Martin.
- All identifiers in the code or database are in English.
- The names should be meaningful and describe the content.
- Tables and table variables end with a plural S. Example: Materials or SalesOrderItems
- Numbering or generalities should be avoided.
- Exactly one name should be specified for each concept. Negative example: The terms 'Article', 'Product' and 'Material' are used for the same thing.
The notation of identifiers
- The special notation with quotation marks should be avoided. It is only used where the simple notation cannot be used. This is particularly the case with the namespace prefixes
/BIC/and/BI0/. - All identifiers in simple notation (=without quotation marks) are internally converted to upper case. So you can use upper/lower case for better readability of words, e.g. SalesOrderItems reads better as salesorderitems.
Hungarian notation and prefixes
In SQLScript, Hungarian notation has no advantage. The distinction between table variables and scalar variables is clearly made on the basis of the position in the source text. The distinction between table variables and DB tables is equally clear.
Indentation and formatting
The readability of the source code is very important for good maintainability and for identifying errors. Indentation with whitespace increases this enormously. The following rules should always be applied:
- For the field list
- Each in the field list is on a separate line
- The fields are neatly aligned in a line
- For nested SQL functions, the parameters are
- Each on a separate line
- Indented below each other
- Clauses and logical operators (
FROM,WHERE,GROUP BY,ORDER BY,ON,AND,ORetc. ) are preceded by a line break. - A blank line must always be inserted between statements.
- Blocks are indented
Example
Cleanly formatted
CONCAT(
CONCAT(
LEFT(
ABAP_UPPER( firstname)
, 1)
, '. ')
, INITCAP( lastname )) AS name,
Without line breaks and indentation.
CONCAT( CONCAT( LEFT( ABAP_UPPER( firstname)
, 1) , '. ') , INITCAP( lastname )) AS name,
Alias names and correlation names
For assigning alias names of columns and for renaming table expressions with correlation names, the keyword AS is mandatory. It increases readability considerably.
- Column aliases should only be used when necessary.
- Correlation names should always be assigned if more than one table is involved. I.e. for JOINs or correlated sub-queries.
Write keywords in full
Keywords are always to be written in the complete form, even if they are optional or a short form exists. Examples:
CROSS JOINinstead of,.ASINNER JOINinstead ofJOINLEFT OUTER JOINinstead ofLEFT JOIN
Avoid long field lists
If you put all the fields in every SELECT, the source code becomes epically long. Instead, we always take all the fields from the previous step with star * and add the new columns.
intab_with_colors = SELECT it.*,
IFNULL(ma.colour, '') AS colour
FROM :intab as it
LEFT OUTER JOIN mara AS ma
ON ma.matnr = it.matnr;
Warning: This does not apply in ABAP. Here, a SELECT * should be avoided .
Parenthesis
As soon as more than one operator is involved in expressions, parentheses must be set. This costs no runtime and increases readability considerably. Example:
What did the developer have in mind here?
WHERE doctype = 'Z001'
AND itemcat = 'A001'
OR itemcat = 'B001'
This is how the database understood it
WHERE ( doctype = 'Z001'
AND itemcat = 'A001' )
OR itemcat = 'B001'
And this is what the developer wanted to achieve
WHERE doctype = 'Z001'
AND ( itemcat = 'A001'
OR itemcat = 'B001 )'
Comments
As a general rule, the line-end comment introduced by the double hyphen -- should always be used in productive code. Block comments with /*...*/, on the other hand, are reserved for working in the SQL console. ABAP line comments (the asterisk * at the beginning of the line) are forbidden, even if they work in AMDP. The reason is that the code can no longer be executed 1:1 in the SQL console.
- Introductory comments describe the structure of the procedure as a whole and in what context it stands.
- Outline comments facilitate navigation in the code. They divide it into sections.
- Explanatory comments describe why something was done or explain complex logic, for example in regular expressions. They support the reading flow.
- Comments that describe the obvious are superfluous.
- Header comments that repeat information from the object catalogue entry and version history are also superfluous.
Commented code is only acceptable during the development phase and has no place in production code.
Dos and Don'ts
The HANA database is optimised to run declarative code. Imperative code runs considerably slower. Primarily because parallelisation is prevented. In addition, imperative code prevents complete optimisation. Therefore:
Imperative code is forbidden
Exceptions require thorough examination.
This leaves only a few statements that may be used in AMDP:
SELECTstatements- Assignment of table variables
- Calling declarative procedures
Dynamic SQL is to be avoided
Dynamic SQL cannot be optimised well by the database. Depending on the use case, there are also good alternatives:
- Separate DB table accesses, see blog article Reusing business logic in AMDP transformation routines.
- Dynamically filter with APPLY_FILTER Function.
Moreover, the complexity of dynamic code is always considerably higher and it is difficult to comprehend it. It also enables code injection attacks.
Break queries into small steps
Complexity in a SELECT query always arises when more than one thing is done at the same time, for example JOIN and aggregation or the multiple JOIN operations at once. This makes it difficult to read and to find errors.
Instead, the queries should be split into several small steps connected by table variables.
Example
One step
The mixture of JOIN and GROUP BY makes it difficult to read. The shorter code feigns simplicity.
DO BEGIN
SELECT u.firstname,
u.lastname,
COUNT(*) AS task_cnt,
MAX(due_date) AS max_dd
FROM users AS u
INNER JOIN tasks AS t
ON u.id = t.assignee
GROUP BY u.firstname,
u.lastname;
END;
Two steps
The decomposition into two trivial steps increases readability. Sensible names for the table variables support this.
DO BEGIN
tasks_per_user = SELECT u.firstname,
u.lastname,
t.id,
t.due_date
FROM users AS u
INNER JOIN tasks AS t
ON u.id = t.assignee;
SELECT firstname,
lastname,
COUNT(id) AS task_cnt,
MAX(due_date) AS max_dd
FROM :tasks_per_user
GROUP BY firstname,
lastname;
END;
Subqueries
Sub-queries are only allowed in the WHERE clause. In particular, in the EXISTS and IN predicates, as well as in comparison value comparison predicates.
In the FROM clause, sub-queries are forbidden. Instead, table variables are to be used. The reason for this is less complexity and better readability.
In the field list, scalar sub-queries are also not allowed. Instead, the data must be added via JOIN. If necessary, these must be prepared in advance in a table variable. The reason for this is performance.
Immediately catch NULL values
The code must be designed in such a way that there are no NULL values in table variables. In the SAP BW tables, we can rely on the fact that NULL is not in the database. Nevertheless, NULL can occur within our routines, e.g. through OUTER JOIN or CASE expressions. With the functions
IFNULL()andCOALESCE()
NULL is replaced by a suitable value.
The predicate IS NULL or IS NOT NULL can be used to filter out records with a NULL value.
All CASE expressions must have an ELSE branch to prevent the NULL value.
Session Variables
The predefined session variables must be read-only. Changing them may affect processing elsewhere in the programme logic.
Self-defined session variables should not be used.
Avoid implicit casting
The HANA database implicitly performs type conversions where necessary. This complicates readability and increases the susceptibility to errors. Therefore, the developer should always use explicit conversions and where possible use the correct type when converting.
Missing type conversions can also lead beginners astray.
Example of wrong conclusions from missing type conversion
SELECT LEFT(current_date, 4) AS year --returns the current year, almost like in ABAP
FROM dummy;
The string function LEFT makes you think that the date is a string internally. But with EXPLAIN we can find out that the database calls a TO_CHAR() function before. And if some joker has changed the default format of DATE beforehand, then the above statement might return 12/0.
Use type-appropriate literals
Constant values are written as literals in the source code. These should always be of the correct data type. The most important literals:
- Strings are written in apostrophes:
'string'. - Unicode strings with leading capital N:
N'Jörg' - Numeric data is written directly without an apostrophe. Decimal separator is the dot.
3.1415 - Time literals are written as a string in the standard format preceded by the data type:
DATE'2022-07-12'.
Example of ambiguous code due to different data type
Note: The HANA database executes this according to unique rules, ambiguous is only for the human reader.
WHERE date < '20090119';
Since SQL cannot compare the data types DATE and VARCHAR, a conversion takes place first. But which one?
- the date into a string ('2009-01-19') or
- the string into a date
So you can clearly see what is happening:
WHERE date < date'2009-01-19';
This makes the comparison easily recognisable between two DATE fields.
Literals with a space
Due to a special feature in the AMDP, literals with only exactly one space behave differently than expected, see this blog article The ABAPVARCHARMODE: Spaces and empty strings in ABAP and SQLScript. Instead, use the SQL function CHAR(32):
SELECT firstname || CHAR(32) || lastname AS name
FROM users;
Restrict data volume early
All statically known filter conditions are applied directly during database access.
Avoid scalar UDFs
Scalar User Defined Functions (UDF) are potentially slow to execute, see the article Why are scalar UDFs so slow?. Therefore, they should not be used.
No conversions and SQL functions in JOIN conditions
An Equi-Join is processed fastest by the database. Every conversion reduces the execution speed. Unfavourable are
- Different data lengths
- Different data types that have to be converted explicitly or implicitly.
- SQL functions such as
LPAD()orLTRIM().
In these cases, check whether the corresponding column can be persisted in a format optimised for the JOIN.
Prefer UNION ALL
If possible, avoid the set operation UNION and use UNION ALL instead. The former removes duplicates from the result set. This is often superfluous, since
- There are no duplicates in the data, e.g. because a field
RECORDorTIMESTAMPis always different or because the data has been selected accordingly. - It does not matter if duplicates occur in the result set, e.g. in the
OUTTABof a transformation routine. Here, the duplicates overwrite each other when the data is activated in the target.
Use Window Functions carefully
Window functions worsen performance for several reasons:
- Optimisation is partially blocked by Window Functions. e.g. filter conditions cannot be pushed down.
- The window functions are executed in the row engine. The data must therefore be copied back and forth between the engines.
In many situations, however, window functions are the best or only solution. Here you have to make sure that the number of data rows to which they are applied is as small as possible. In other words, all filtering should take place before the WF.
If the WF refers to a very large database table, in transformation routines a preceding INNER JOIN with the INTAB can effectively limit the data volume.
Database hints
Database should not be used.
If SAP recommends a hint as a reaction to a ticket, it must be checked after each Database update whether it is still necessary or helpful.
Especially for AMDP transformation routines
The following topics only refer to AMDP transformation routines in BW/4HANA or BW on HANA. They have no relevance for general AMDP and SQLScript development.
Maximum one routine
The logic in a transformation should be implemented as centrally as possible in one place. For a better overview, distribution across many places should be avoided. This applies not only to routines but also to formulas.
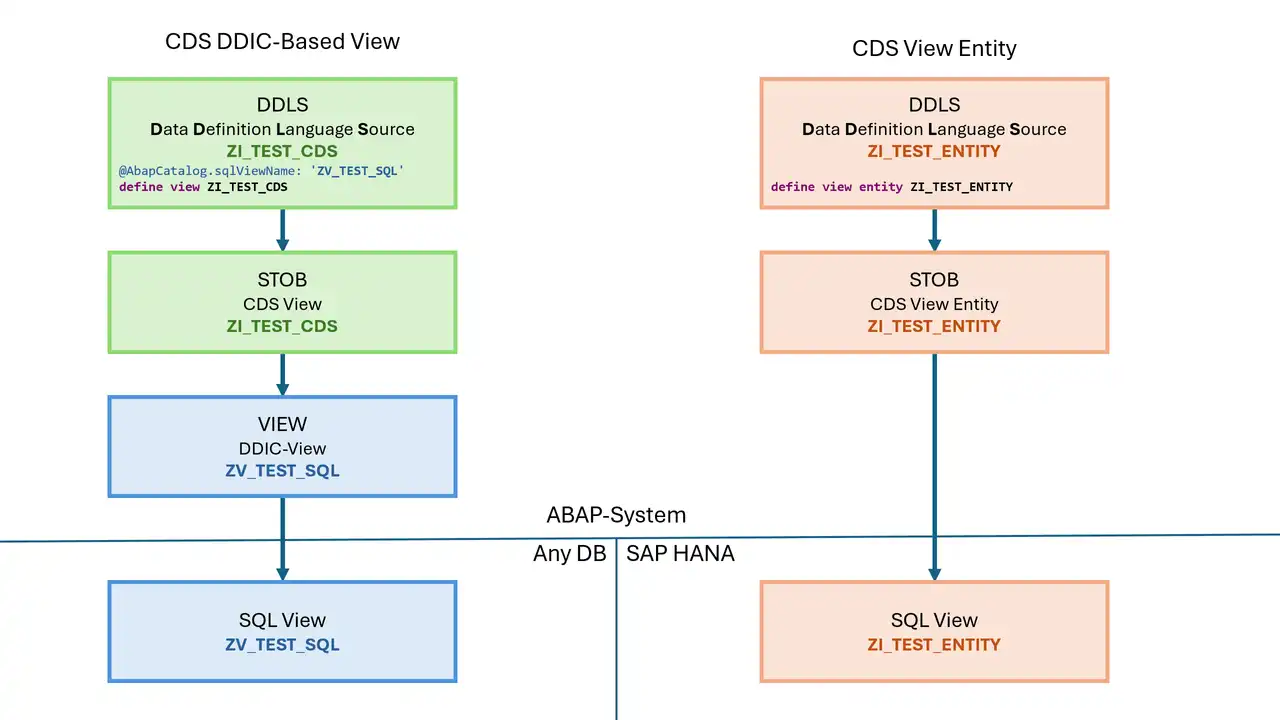
Use the DDic-Based CDS Views
The new CDS-View Entities (since ABAP release 7.55) have a big disadvantage in AMDP routines. They can be used there to read data. But it is not possible to copy the source code into the SQL console and execute it there.
Hence the SQL view of the old DDic-based CDS-views should always be used for database access via CDS.
Structure of the routines
AMDP transformation routines should be subdivided into several steps. The following structure has proven to be useful:
- Input projections - All tables named in the
USINGclause are loaded into a table variable at the very beginning. The following applies:- Only include the columns that will be needed later
- Necessary calculations can be done here
- Renaming of columns could be usefull to use the Star in the fieldlist later on.
- The data is already restricted as far as possible
- Many small steps - In each step process only one aspect at a time. The data from the previous step can be taken along with
*. - Output projection - At the very end there is an output projection. There is no more logic here. It is only a matter of putting the fields in the right order for the
OUTTAB.
Summary
These guidelines set guardrails within which one can safely operate. It describes many different aspects that should be considered in AMDP and SQLScript development. It should only be deviated from for good reasons.
However, they do not explain the basic concepts behind the SQLScript programming language and the AMDP framework, the procedure for creating transformation routines, and all the technical details one should know in order to write good transformation routines. This requires a sound education of the developers.
Feedback welcome
I welcome any feedback and constructive discussions on these topics. Please send me an email or use the contact form if you have any comments.
Useful links
Wikipedia
Clean Code
Amazon
Book: Clean Code
SAP Reference Documentation SQLScript
Best Practices for Using SQLScript