Es begegnen einem häufig GUID und UUID in SAP HANA und im S/4HANA als Schlüsselfelder. Solange diese nicht interpretiert bzw. konvertiert werden müssen, ist das für die SAP HANA kein Problem. Voraussetzung dafür ist ein einheitlicher Datentyp. Es gibt aber unterschiedliche Formate für UUID. Für diese gibt es in der ABAP-Welt eine Klasse zum Konvertieren. In der SAP HANA ist die Umrechnung nicht so einfach.
Ausgangspunkt und Anlass für diesen Artikel ist eine Frage aus der SAP Community. Darin geht es um die Frage, wie ein JOIN zwischen den unterschiedlichen UUID Formaten möglich ist.
Was sind UUID und GUID
Die sogenannten Universally Unique Identifiers (UUID) oder Globally Unique Identifiers (GUID) werden gerne als Schlüssel zur eindeutigen Identifikation von Informationen verwendet. Der riesige Vorteil liegt in der Eindeutigkeit einer UUID. Also der Tatsache, dass eine anhand der Spezifikationen generierte UUID faktisch nicht noch einmal existiert. Damit ist es möglich, Datenbestände aus unterschiedlichsten Computersystemen zusammenzuführen, ohne das Risiko einer Schlüsselkollision.
Der Preis für diese Eindeutigkeit ist jedoch ein Format, das für menschliche Leser eine Zumutung ist. Niemand kann sich eine UUID merken und schon der Vergleich von zwei UUID ist mühsam, wenn sie nicht direkt untereinander stehen.
Formate von UUID in SAP Systemen
Es gibt mehrere übliche Formate für UUID in SAP Systemen, die ineinander konvertiert werden können. Wir bezeichnen diese im Folgenden nach der Konvention, die die SAP für die Signatur der ABAP Klasse CL_SYSTEM_UUID verwendet. Grundsätzlich handelt es sich bei allen Formaten um die Darstellung von 16 Bytes auf unterschiedliche Art und Weise.
X16 - Das Byte Format
In SAP HANA heißt der Datentyp für Bytes VARBINARY. Dieser entspricht im ABAP dem eingebaute, byteartige Datentyp x. Diese Datentypen können die 16 Bytes eigentlich am besten speichern. Allerdings tun sich die Menschen sehr schwer mit der Interpretation. Spätestens bei der Ausgabe als Zeichenkette wird der X16 normalerweise in 32 Hexadezimal Werten dargestellt.
C32 - Die Bytes als HEX-Zeichen, aka. Base 16 Encoding
Die Konvertierung von einem Byte in zwei Hexadezimalwerte wird in RFC 4648 beschrieben. Diese ist sehr intuitiv, da aus einem Byte mit 8 Bit exakt zwei Werte zu je 4 Bit werden. Das Alphabet für diese 16 unterschiedlichen Werte besteht aus den Ziffern 0 bis 9 und den Buchstaben A bis F. Man findet diese Darstellung sehr häufig für die Anzeige binärer Daten.
C36 - Die HEX-Zeichen gruppiert
Der einzige Unterschied zwischen C32 und C36 ist, dass die Zeichen in Blöcken gruppiert sind. Die vier Trennzeichen beanspruchen die zusätzlichen Zeichen. Das C36 Format wird von SAP CAP (Cloud Application Programming Model) verwendet. Entsprechend gibt es auch einen CDS HANA Datentyp UUID, der in der HANA auf VARCHAR(36) abgebildet wird.
C32: 12837204B4991EDC9FC0675639081656
C36: 12837204-B499-1EDC-9FC0-675639081656
Die Konvertierung zwischen C32 nach C36 ist denkbar einfach. Aus einer Antwort auf eine Frage zu diesem Thema in der SAP Community habe ich diesen Vorschlag für die Konvertierung mittels regulären Ausdrücken gefunden. Nebenbei werden die Buchstaben in Kleinbuchstaben konvertiert.
SELECT
LOWER(
REPLACE_REGEXPR('([0-9A-F]{8})([0-9A-F]{4})([0-9A-F]{4})([0-9A-F]{4})([0-9A-F]{12})' FLAG 'i'
IN SYSUUID WITH '\1-\2-\3-\4-\5')
)
FROM DUMMY;
Da die Darstellung von C32 und C36 relativ lang ist, liegt die Idee nahe, ein größeres Alphabet zu verwenden und somit kürzere Codes zu erzeugen. Das bringt uns zur nächsten Codierung:
C22 - Die Bytes codiert mit dem Base 64 Encoding
Der Unterschied zu Base 16 liegt darin, dass jetzt 64 statt 16 unterschiedliche Zeichen genutzt sind. Das sind laut RFC 4648 die 10 Ziffern 0 bis 9, die 26 Kleinbuchstaben a bis z, die 26 Großbuchstaben A bis Z und noch die Sonderzeichen / und +. Bei der SAP Implementierung gibt es eine kleine Abwandlung, die Pseudo Base 64 genannt wird: Die Reihenfolgen der Zeichen ist etwas anders und es werden die Sonderzeichen { und } verwendet. Damit können also nicht nur 4 Bit sondern ganze 6 Bit in einem Zeichen codiert werden. Somit kann man mit Base 64 Encoding also 3 Bytes als 4 Zeichen darstellen. Im Hex-Format wären es immerhin 6 Zeichen. Die Verkürzung ist signifikant. Bei den 16 Byte UUID sind es entsprechend 22 statt 32 Zeichen.
Die Umrechnung von C32 nach C22 ist mit deklarativem SQL relativ einfach möglich. Den Algorithmus hierzu habe ich im Forum stackoverflow in einer Antwort von Hubert Englmaier gefunden. Basis dieser Implementierung ist die Idee, dass man sich eine Mappingtabelle erstellen kann. Wenn man von Base 16 Encoding ausgeht, dann kann man daraus jeweils 3 Zeichen (=1,5 Bytes) in die entsprechenden 2 codierten Zeichen aus dem Base 64 Alphabet zuordnen. Zur Umrechnung muss dann die UUID im C32 Format entsprechend in 3-er Blöcke zerlegt werden. Damit das passt, wird am Ende mit einer 0 aufgefüllt. Für jeden dieser 11 Blöcke wird die Mappingtabelle einmal an die Originaldaten gejoint und das Ergebnis des Mapping verkettet.
Die Mappingtabelle hat 4096 Einträge und ist somit relativ klein. Der 11-fache Join ist sicherlich nicht super schnell, aber für eine Verarbeitung im Backend sollte das auch für große Datenvolumen vollkommen ausreichen.
Der Konvertierung von C32 nach C22 bzw. von Base 16 Encoding zu Base 64 Encoding
Die erste 11 Zeilen legen die Mappingtabellen an und füllen diese mit den passenden Werten. Für die ersten 4096 Zahlen wird einerseits der 3-stellige Hexadezimalwert berechnet und andererseits die beiden zugehörigen Buchstaben aus dem Base 64 Alphabet. Dieser Schritt muss initial nur genau einmal durchgeführt werden.
Der zweite Teil im anonymen Block berechnet für die Tabellenvariable LT_SRC die C22 UUID aus der C32 UUID, in dem an die Abschnitte zu jeweils 3 Hex-Zeichen die Mappingtabelle gejoint wird. In der Feldliste werden die gemappten Werte verkettet. Diese Logik lässt sich natürlich auch so anpassen, das in der anderen Richtung von C22 nach C32 gemappt wird.
CREATE TABLE uuid_conv (hex nvarchar(3), c22 nvarchar(2));
INSERT INTO uuid_conv
SELECT RIGHT(numtohex(generated_period_start), 3) as hex,
SUBSTR( N'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz{}',
TO_INT(generated_period_start / 64 ) + 1,
1)
||SUBSTR( N'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz{}',
MOD(generated_period_start , 64 ) + 1,
1) as c22
FROM series_generate_integer(1, 0, 4095);
DO BEGIN
lt_src = SELECT '0050563C56401D36A348F362444845FC' AS uuid FROM DUMMY;
select uuid,
block_a.c22 || block_b.c22 || block_c.c22 ||
block_d.c22 || block_e.c22 || block_f.c22 ||
block_g.c22 || block_h.c22 || block_i.c22 ||
block_j.c22 || block_k.c22 AS uuid_c22
FROM :lt_src AS src
INNER JOIN uuid_conv AS block_a ON block_a.hex = SUBSTR(src.uuid, 1, 3)
INNER JOIN uuid_conv AS block_b ON block_b.hex = SUBSTR(src.uuid, 4, 3)
INNER JOIN uuid_conv AS block_c ON block_c.hex = SUBSTR(src.uuid, 7, 3)
INNER JOIN uuid_conv AS block_d ON block_d.hex = SUBSTR(src.uuid, 10, 3)
INNER JOIN uuid_conv AS block_e ON block_e.hex = SUBSTR(src.uuid, 13, 3)
INNER JOIN uuid_conv AS block_f ON block_f.hex = SUBSTR(src.uuid, 16, 3)
INNER JOIN uuid_conv AS block_g ON block_g.hex = SUBSTR(src.uuid, 19, 3)
INNER JOIN uuid_conv AS block_h ON block_h.hex = SUBSTR(src.uuid, 22, 3)
INNER JOIN uuid_conv AS block_i ON block_i.hex = SUBSTR(src.uuid, 25, 3)
INNER JOIN uuid_conv AS block_j ON block_j.hex = SUBSTR(src.uuid, 28, 3)
INNER JOIN uuid_conv AS block_k ON block_k.hex = SUBSTR(src.uuid, 31, 2)||'0' ;
END;
C26 - Die Codierung mit Base 32
Eigentlich funktioniert die Base 32 Codierung genau analog zur Base 64 Codierung. Das Alphabet mit 32 Zeichen umfasst die Großbuchstaben A bis Z und die Ziffern 2 bis 7. Da jeder Buchstabe 5 Bit repräsentiert, ist die Codierung jeweils nur in Blöcken zu 5 Byte (also 40 Bit) möglich. Eine entsprechende Mappingtabelle müsste 1.099.511.627.776 Einträge enthalten. Das ist eine Größenordnung, die für eine SAP HANA Datenbank nicht mehr praktikabel ist. Mir sind bislang nur imperative Lösungen für die Konvertierung eingefallen, was für Massendaten nicht praktikabel ist.
Beispiel für die unterschiedlichen UUID Formate
X16: 12837204B4991EDC9FC0675639081656
C22: 4eDo1BIP7joVm6TMEGWMLW
C26: CKBXEBFUTEPNZH6AM5LDSCAWKY
C32: 12837204B4991EDC9FC0675639081656
C36: 12837204-B499-1EDC-9FC0-675639081656
Erzeugung von UUID
UUID in SAP HANA erzeugen
Um eine eindeutige UUID in SAP HANA zu generieren, gibt es die SQL-Funktion SYSUUID. Sie gehört zu den wenigen SQL-Funktionen, die ohne Klammern aufgerufen werden. Das Ergebnis wird eigentlich binär als X16 zurückgegeben. Mit einer Funktion TO_VARCHAR(SYSUUID) kann dieses in das C32 Format konvertiert werden.
UUID in SAP ABAP erzeugen
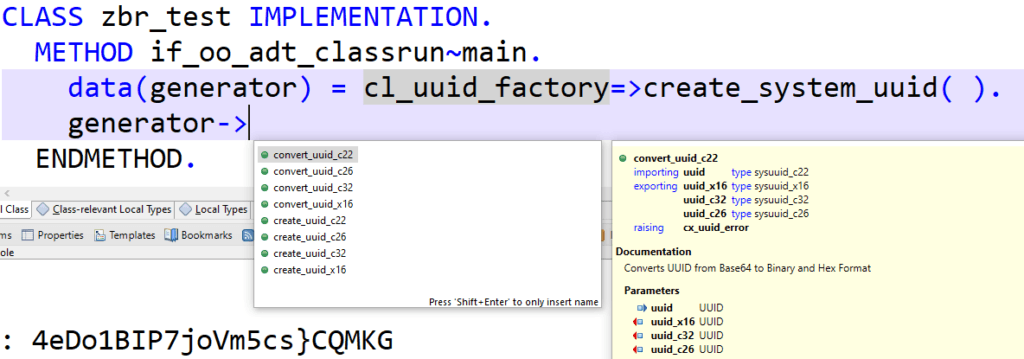
UUID in SAP ABAP Cloud erzeugen bzw. konvertieren.
In ABAP können mit den Methoden der bereits oben erwähnten Klasse CL_SYSTEM_UUID eindeutige UUID in den oben beschriebenen Formaten erzeugt werden. Auch die Konvertierung zwischen diesen Formaten ist mit den entsprechenden Methoden möglich.
Alternativ dazu kann man über die CL_UUID_FACTORY gehen und sich eine Instanz einer Generator Klasse besorgen, siehe Abbildung.
Verarbeitung von UUID
Grundsätzlich sollten Sie keine Eigenschaften von UUID nutzen, außer der Tatsache das sie eindeutig sind. Die Algorithmen sichern keine feste Reihenfolge der vergebenen UUID zu. Eine Weiterverarbeitung sollte zur Laufzeit vermieden werden. Wenn unterschiedliche Formate für die gleiche UUID vorliegen, sollte man diese vereinheitlicht persistieren. Die Konvertierung zur Laufzeit ist für Massendaten nicht zu empfehlen.
Fazit
UUID sind praktisch, weil sie global eindeutig sind. Damit können Datenbestände unterschiedlichster Herkunft zusammengeführt werden, ohne dass man Kollisionen befürchten muss. Der Preis dafür sind für Menschen schwer lesbare Codierungen und im schlimmsten Fall unterschiedliche Formate. Warum die UUID in SAP unterschiedliche Codierungen haben bzw. die SAP diese auch anbietet, ist mir ein Rätsel. Die Nachteile der Konvertierung überwiegen die Vorteile von etwas kürzeren Codes bei den heutigen Speicher- und Rechnerkapazitäten bei weitem.