With BW/4HANA 2.0 I observed that the packet size of the DTPs is dynamically suggested by the system. Figure 1 shows, for example, a suggested size of 1,311,000 data records. In this way, the system dares to go into an order of scale, that is better than the former fixed standard value of 100,000 rows based on my own practical experience.
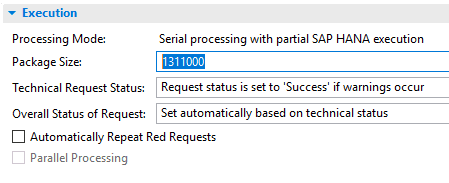
Figure1: Suggested Package Size for a DTP
In this blog post I have collected some useful information regarding the DTP package size and added an own example with a measurement series.
Actual packet size for HANA execution
When HANA executes DTPs, we only see exactly one number of records for each packet in the monitor. For ABAP execution, a number of records was specified here for each substep: Extraction, transformation, insertion, and so on. However, these substeps can no longer be distinguished in HANA execution. All logic from extraction, transformation rules, routines, and this possibly over several levels, is included in a single CalculationScenario, from which the data is read. And this scenario is optimized as a whole. This means that we no longer have individual values for the respective steps. And this also explains why the number of data records in the monitor is only displayed after a whole package has been processed, and not step by step as was the case in the past.
How much data is actually processed at once depends on several parameters. The package size in the DTP specifies the number of data records in the source. Normally, N packages of this size are formed, the last of the packages is correspondingly smaller.
If the data is retrieved request by request in delta mode, this procedure is repeated for each individual request. This means that for each request there is a package that is not the full package size.
If semantic partitioning is set, as many partitions as necessary are inserted into each package until the package size is exceeded. If the partitioning criteria are chosen inappropriately, this can result in enormously large packages or uneven package sizes.
However, the actual package size is also influenced by the transformation routines. If, for example, a filter with a WHERE is applied to the INTAB, the number of data records in the packet is reduced accordingly. This condition is pressed down into the extraction of the data. However, since the packet building takes place before the individual packets are processed, the packets are effectively reduced by the filter criterion.
Conversely, it can also happen that the actual packet size is increased by the logic in the routines. This is the case, for example, if data is multiplied by a join or if data is transposed from a key figure model to a corresponding characteristic model.
The actual number of data records is important for good performance.
Optimal Package Size for HANA Execution
An unfavorable package size increases the runtime. With HANA execution, the packages can be considerably larger than with ABAP execution. An order of scale of 1,000,000 data records is in most cases a good start value if you do not receive any proposals from the system. It is important that this is the actual number of data records. If your routines filter out 90% of the data records, you should take this into account in the package size of the DTPs. If the packages become too large, the number of parallel processes may not be used. You can see an example of this in the following example.
The optimum package size can only be determined by tests. These tests should be performed on the production system with real data.
Example of a DTP with Processing Logic
In the following, I show the runtimes for a DTP that contains a transformation that creates 16 records from one source record by transposing it. This is necessary to convert the PCA plan data from a key figure based model into a characteristic based model in which each data record represents a period. In the example, there are 1,994,590 data records in the source, from which 31,913,440 data records are converted in the target by the routine.
| Package Size in the DTP | Actual number of Data Records | Runtime in Seconds |
| 10.000 | 160.000 | 243 |
| 62.500 | 1.000.000 | 155 |
| 100.000 | 1.600.000 | 138 |
| 1.000.000 | 16.000.000 | 258 |
Table 1: Runtime depending on the Package Size
The default value of the BW/4HANA system for the DTP greetings is 1,000,000 data records. However, this is no longer optimal due to the duplication of the data records. If we choose a package size instead, so that the actual number of data records corresponds to approx. 1,000,000, then the runtime is considerably better. In our example, the optimum is 1.6 million actual records.
Influence of the Number of Work Processes in HANA Execution
In addition to the package size, the number of work processes also has an influence on the total runtime for a DTP. However, the effect of doubling the number of work processes is by far not as great as you would naively expect:
For the above example, I have increased the number of work processes from 3 to 6. This shortens the runtime from 138 seconds by only 14% to 121 seconds.
From ABAP execution, we know here a halfway linear dependency on runtime and number of work processes. When you execute the process chains, you must always make sure that the total number of background processes (type BTC) is sufficient.
Summary
The packet size is an important parameter for optimizing the DTP runtime. With the HANA version, we can now choose larger packages. The default value of BW/4HANA 2.0 must sometimes be adjusted, especially if the transformation logic changes the actual number of data records. Often the only thing that helps here is to try it out.