


You will often encounter GUID and UUID in SAP HANA and in S/4HANA as key fields. As long as these do not have to be interpreted or converted, this is not a problem for SAP HANA. The prerequisite for this is a uniform data type. But there are different formats for UUID. There is a special class for converting these different formats in the ABAP world. In SAP HANA, however, the conversion is not so simple.
The starting point and reason for this article is a question from the SAP community. This deals with the question, how a JOIN between the different UUID formats is possible.
What are UUID and GUID
The so-called Universally Unique Identifiers (UUID) or Globally Unique Identifiers (GUID) are often used as keys for the unique identification of information. The huge advantage is the uniqueness of a UUID. In other words, the fact that a UUID generated on the basis of the specifications in fact does not exist twice. This makes it possible to merge data sets from totaly different computer systems without the risk of key collision.
The price for this unambiguity, however, is a format that is a real challenge for human readers. No one can remember a UUID and even comparing two UUIDs is tedious if they are not written exactly beneath each other.
Formats of UUID in SAP systems
There are several common formats for UUID in SAP systems, each of them can be converted into all the other ones. In the following we designate these formats according to the convention used by SAP for the signature of the ABAP class CL_SYSTEM_UUID. Basically, all formats are about to represent 16 bytes in different ways.
X16 - The Byte Format
In SAP HANA, the data type for bytes is called VARBINARY. This corresponds in ABAP to the built-in, byte-type data type x. These data types are the best in storing the 16 bytes. However, they are quite difficult to be interpreted by humans. When it comes to editing them as a string, the X16 is normally represented in 32 hexadecimal values.
C32 - The bytes as HEX characters, aka. Base 16 Encoding
The conversion of one byte into two hexadecimal values is described in RFC 4648. This is very intuitive, because one byte with 8 bits becomes exactly two values with 4 bits each. The alphabet for these 16 different values consists of the digits 0 to 9 and the letters A to F. You can find this representation very often for the display of binary data.
C36 - The HEX characters grouped
The only difference between C32 and C36 is that the characters are grouped in blocks. The four separators claim the additional characters:
C32: 12837204B4991EDC9FC0675639081656
C36: 12837204-B499-1EDC-9FC0-675639081656
Since the representation of C32 and C36 is relatively long, there is the idea to use a larger alphabet and thus generate shorter codes. This brings us to the next coding:
C22 - The bytes are encoded with the Base 64 Encoding
The difference to Base 16 is that now 64 instead of 16 different characters are used. According to RFC 4648, these are the 10 digits 0 to 9, the 26 lowercase letters a to z, the 26 uppercase letters A to Z, and the special characters / and +. In the SAP implementation there is a small modification called Pseudo Base 64: The sequence of characters is slightly different and the special characters { and } are used. This means that not only 4 bits but a whole 6 bits can be encoded in one character. Thus, 3 bytes can be represented as 4 characters using Base 64 Encoding. In hex format it would be 6 characters. The shortening is significant. Regarding the 16-byte UUID, there are correspondingly 22 instead of 32 characters.
The conversion from C32 to C22 is relatively easy with declarative SQL. I found the algorithm for this in the forum 'stackoverflow' in a reply by Hubert Englmaier. The basis of this implementation is a mapping table. If you start from Base 16 Encoding, then you can assign 3 characters (=1.5 bytes) each to the corresponding 2 encoded characters from the Base 64 alphabet. For conversion, the UUID in C32 format must then be broken down accordingly into blocks of 3. To make this fit, it is padded with a 0 at the end. For each of these 11 blocks, the mapping table is joined once to the original data and the result of the mapping is concatenated.
The mapping table has 4096 entries and is therefore relatively small. The 11-fold join is certainly not super fast, but it should be perfectly sufficient for processing in the backend, even for large data volumes.
The conversion from C32 to C22 or from Base 16 Encoding to Base 64 Encoding
The first 11 lines create the mapping tables and fill them with the appropriate values. For the first 4096 numbers, the 3-digit hexadecimal value is calculated on the one hand and the two associated letters from the Base 64 alphabet on the other hand. This initial step has to be performed only once.
The second part in the anonymous block calculates the C22 UUID from the C32 UUID for the table variable LT_SRC by joining the mapping table to the sections of 3 hex characters each. In the field list the mapped values are being concatenated. Of course, this logic can also be modified in a way that enables you to map from C22 to C32 - just the opposite direction.
CREATE TABLE uuid\_conv (hex nvarchar(3), c22 nvarchar(2));
INSERT INTO uuid\_conv
SELECT RIGHT(numtohex(generated\_period\_start), 3) as hex,
SUBSTR( N'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz{}',
TO\_INT(generated\_period\_start / 64 ) + 1,
1)
||SUBSTR( N'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz{}',
MOD(generated\_period\_start , 64 ) + 1,
1) as c22
FROM series\_generate\_integer(1, 0, 4095);
DO BEGIN
lt\_src = SELECT '0050563C56401D36A348F362444845FC' AS uuid FROM DUMMY;
select uuid,
block\_a.c22 || block\_b.c22 || block\_c.c22 ||
block\_d.c22 || block\_e.c22 || block\_f.c22 ||
block\_g.c22 || block\_h.c22 || block\_i.c22 ||
block\_j.c22 || block\_k.c22 AS uuid\_c22
FROM :lt\_src AS src
INNER JOIN uuid\_conv AS block\_a ON block\_a.hex = SUBSTR(src.uuid, 1, 3)
INNER JOIN uuid\_conv AS block\_b ON block\_b.hex = SUBSTR(src.uuid, 4, 3)
INNER JOIN uuid\_conv AS block\_c ON block\_c.hex = SUBSTR(src.uuid, 7, 3)
INNER JOIN uuid\_conv AS block\_d ON block\_d.hex = SUBSTR(src.uuid, 10, 3)
INNER JOIN uuid\_conv AS block\_e ON block\_e.hex = SUBSTR(src.uuid, 13, 3)
INNER JOIN uuid\_conv AS block\_f ON block\_f.hex = SUBSTR(src.uuid, 16, 3)
INNER JOIN uuid\_conv AS block\_g ON block\_g.hex = SUBSTR(src.uuid, 19, 3)
INNER JOIN uuid\_conv AS block\_h ON block\_h.hex = SUBSTR(src.uuid, 22, 3)
INNER JOIN uuid\_conv AS block\_i ON block\_i.hex = SUBSTR(src.uuid, 25, 3)
INNER JOIN uuid\_conv AS block\_j ON block\_j.hex = SUBSTR(src.uuid, 28, 3)
INNER JOIN uuid\_conv AS block\_k ON block\_k.hex = SUBSTR(src.uuid, 31, 2)||'0' ;
END;
C26 - Coding with base 32
Actually, Base 32 encoding works exactly analogous to Base 64 encoding. The alphabet with 32 characters includes the capital letters A to Z and the digits 2 to 7. Since each character represents 5 bits, the coding is only possible in blocks of 5 bytes (i.e. 40 bits). A corresponding mapping table would have to contain 1,099,511,627,776 entries. Working on this scale is no longer practical for an SAP HANA database. So far, I have only considered imperative solutions for conversion here, which is not practical for bulk data.
Example of the different UUID formats
X16: 12837204B4991EDC9FC0675639081656
C22: 4eDo1BIP7joVm6TMEGWMLW
C26: CKBXEBFUTEPNZH6AM5LDSCAWKY
C32: 12837204B4991EDC9FC0675639081656
C36: 12837204-B499-1EDC-9FC0-675639081656
Generating an UUID
Generating UUID in SAP HANA
You can use the SQL function SYSUUID in order to generate a unique UUID in SAP HANA. It is one of the few SQL functions that are called without brackets. The result is actually returned in binary as X16. With the function TO_VARCHAR(SYSUUID) this can be converted into the C32 format.
Generating UUID in SAP ABAP
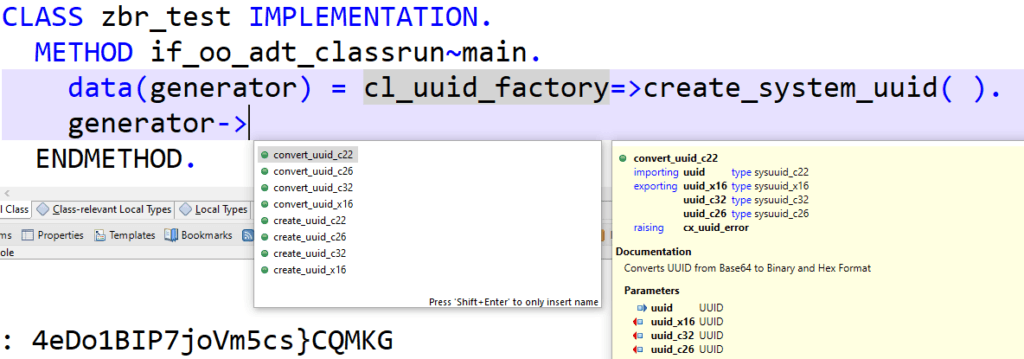
Create or convert UUID in SAP ABAP Cloud.
In ABAP , you can use the methods of the above mentioned class CL_SYSTEM_UUID in order to generate a unique UUID in the described formats. Conversion between these formats is also possible using the appropriate methods.
Alternatively, you can go via the CL_UUID_FACTORY and get an instance of a generator class, see figure.
UUID processing
Basically, you should not use any features of UUID except of the fact that they are unique. The algorithms do not ensure a fixed order of the assigned UUID. Further processing should be avoided at runtime. If there are different formats for the same UUID, you should persist them in a unified way. Conversion at runtime is not recommended for bulk data.
Conclusion
UUID are convenient because they are globally unique. This makes it possible to merge data sets from many different sources without fear of collisions. The price for this is a hardly readable code (for humans)and, in the worst case, different formats. The fact that SAP offers a range of different encodings for UUID is a mystery to me. The disadvantages of conversion outperform the advantages of a slightly shorter code regarding today's memory and computer capacities.












