When loading data from source systems, there are requirements in SAP BW that are often repeated at the field level. This includes, above all, logics for cleaning up and processing the data, such as:
- Add and remove leading zeros
- Case distinctions
- Remove spaces at the beginning or end
- Conversion to capital letters
- Derive one field from another with solid pattern substrings, e.g. COAREA ==> COUNTRY
- Derive time characteristics
The following listing shows a few examples in the source code:
outTab = SELECT TO_VARCHAR(TO_DATE(calday), 'YYYYMM') AS calmonth,
"/BIC/SRCSYS",
...
"/BIC/CURTYP",
LEFT("/BIC/COAREA", 2) AS "/BIC/COUNTRY",
SUBSTRING("/BIC/BI_PROFCT", 9, 2) as "/BIC/PCACCID",
CASE SUBSTRING("/BIC/PROFCT", 8, 3)
when '643' then '1'
when '655' then '1'
when '641' then '2'
when '651' then '2'
when '643' then '3'
when '655' then '3'
else ''
end as "/BIC/PRBY',
...
FROM :intab;
What all these requirements have in common is that they
- Easy to implement in SQLScript with existing SQL capabilities
- often repeat
- can be executed very quickly by SAP HANA as long as they are implemented directly in the transformation routines.
DRY - Don't Repeat Yourself
The well-known DRY principle should actually come into play here. So that you don't repeat the source code all the time. In the field list, the scalar, custom functions (UDF) are available for this purpose. Until recently, these were not an issue for the transformation routines in the BW, because they can only be created with the AMDP Framework since AS ABAP Release 753 ((SAP documentation for AMDP functions)). But scalar UDFs would be ideal for precisely these requirements. This ensures a uniform implementation. And in the source code, one comes from a technical description of the expressions to a technical view:
outTab = SELECT "ZCL_CALDAY=>TO_CALMONTH"(calday) AS calday
"/BIC/SRCSYS",
...
"/BIC/CURTYP",
"ZCL_COAREA=>TO_COUNTRY"("/BIC/COAREA") AS "/BIC/COUNTRY",
"ZCL_PROFCT=>TO_PCACCID"(/BIC/PROFCT") as "/BIC/PCACCID",
"ZCL_PROFCT=>TO_PRBY"(/BIC/PROFCT") as "/BIC/PRBY',
...
FROM :intab;
The outsourced functions look much more elegant. And they are also superior from the point of view of maintenance. For example, if another profit center appears in the list, there is exactly one feature that needs to be adjusted. Using the example of ZCL_PROFCT=>TO_PRBY I show such a scalar AMDP function:
CLASS zcl_profct DEFINITION
PUBLIC
FINAL
CREATE PUBLIC .
PUBLIC SECTION.
INTERFACES if_amdp_marker_hdb.
METHODS to_prby IMPORTING VALUE(iv_profct) TYPE char10
RETURNING VALUE(rv_prby) TYPE char1.
ENDCLASS.
CLASS zcl_profct IMPLEMENTATION.
METHOD to_prby BY DATABASE FUNCTION FOR HDB LANGUAGE SQLSCRIPT OPTIONS DETERMINISTIC READ-ONLY.
rv_prby = case SUBSTRING(:iv_profct, 8, 3)
WHEN '643' then '1'
WHEN '655' then '1'
WHEN '641' then '2'
WHEN '651' then '2'
WHEN '643' then '3'
WHEN '655' then '3'
ELSE ''
END ;
ENDMETHOD.
ENDCLASS.
The example shows that the function is just a simple "shell" for a CASE expression. By the way, outsourcing to the ABAP world also makes it easy to write UnitTests for the functions. Since the functions in the database are only generated from the ABAP on the first call, UnitTests are also suitable for this purpose. ((I deliberately do not use data items generated by BW-InfoObjects to minimize dependency.))
Elegant but slow
As elegant as the outsourcing of logic in UDFs is, the concept is unfortunately not to be used for large amounts of data. This is because the UDFs have a significant influence on the duration. I would like to show this in another expression from the example above:
TO_VARCHAR(TO_DATE(calday), 'YYYYMM')
This simple expression converts an ABAP DATS value into a SQLScript date, which is then output to a yYYYMM string. This corresponds to the format of the popular InfoObject CALMONTH.
Example: 20200928 ==> 202009
For this purpose, I create an AMDP UDF according to the above pattern:
METHOD to_calmonth BY DATABASE FUNCTION FOR HDB LANGUAGE SQLSCRIPT OPTIONS DETERMINISTIC READ-ONLY.
rv_result = TO_VARCHAR(TO_DATE(:iv_calday), 'YYYYMM');
ENDMETHOD.
I made two queries in the SQL console on a small BW table with about 3 million entries: one directly with the printout and one with the function call.
Without UDF
do begin
select budat,
TO_VARCHAR(TO_DATE(budat), 'YYYYMM'),
account,
amount,
curr
from "/BIC/AZBR_E1_S2";
end;
Console
Statement 'do begin select budat, TO_VARCHAR(TO_DATE(budat), 'YYYYMM'),
account, amount, curr from ...'
successfully executed in 501 ms 237 µs (server processing time: 801
ms 664 µs)
Fetched 1000 row(s) in 102 ms 468 µs (server processing time: 0 ms 677 µs)
Result limited to 1000 row(s) due to value configured in the Preferences
With UDF
do begin
select budat,
"ZCL_CALDAY=>TO_CALMONTH"(BUDAT),
account,
amount,
curr
from "/BIC/AZBR_E1_S2";
end;
Console
Statement 'do begin select budat, "ZCL_CALDAY=>TO_CALMONTH"(BUDAT),
account, amount, curr from ...'
successfully executed in 2:09.418 minutes (server processing time:
4:18.632 minutes)
Fetched 1000 row(s) in 103 ms 144 µs (server processing time: 0 ms 675 µs)
Result limited to 1000 row(s) due to value configured in the Preferences
The runtimes are so different that you actually have to assume a bug. Because the complexity of the Besipiel is minimal. With less complexity, I don't need UDF anymore. What I find amazing:
- In fact, there are only 365 different values of BUDAT in the table. Thus, the system has the information: With the same input, the same result should also be delivered. See ((SAP documentation for the CREATE FUNCTION statement )). This should run it a maximum of 365 times and then be read out of the buffer, right?
- I would also have expected only the dictionary of the column to be converted, so each value exactly once.
- If you had replaced the function call with the function content with a primitive text editor with simple search/replacement, you are over 100 times faster. The Optimizer of an SAP HANA 7((Scalar User Defined Functions in SAP HANA - The first blog post on the topic of Rich Heilmann from 2013)) should get this years after the introduction of scalar UDFs, right?
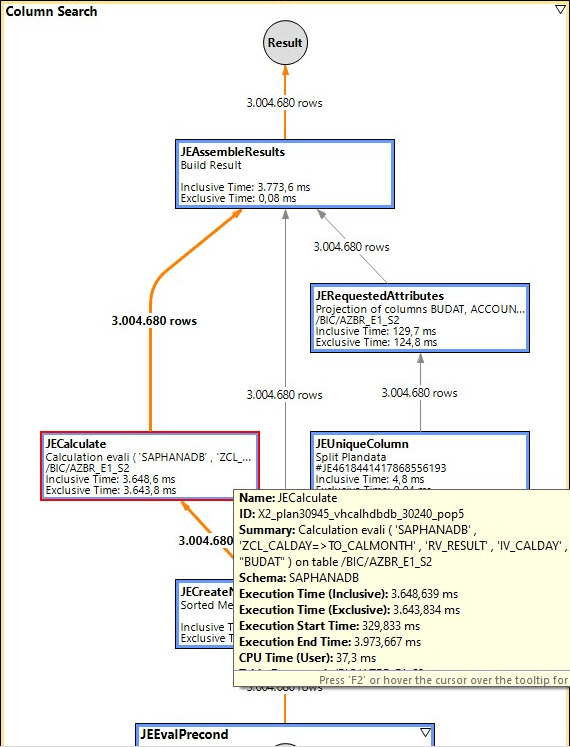
In order to fully document the whole thing, I also did the analysis with PlanViz.
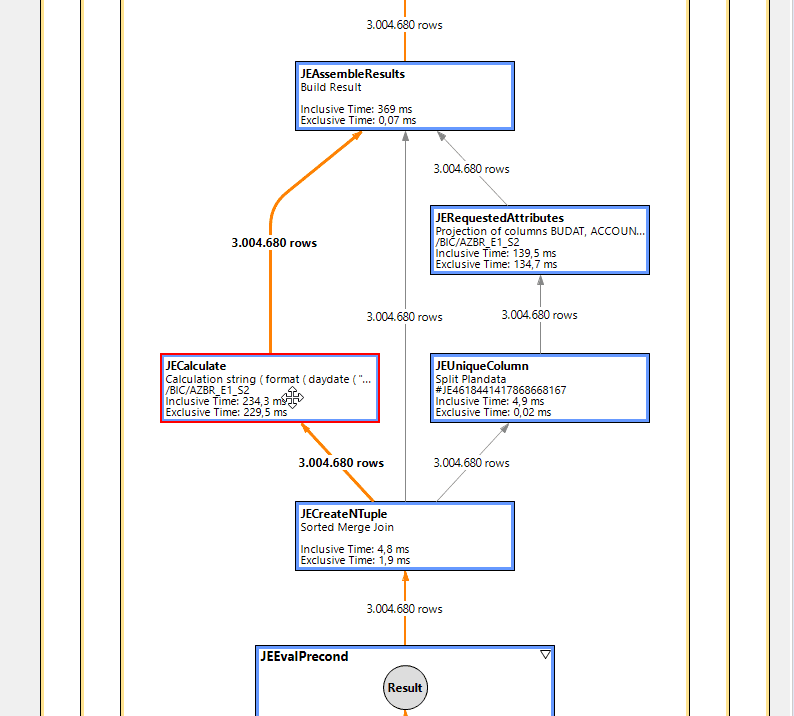
PlanViz of the query with expression
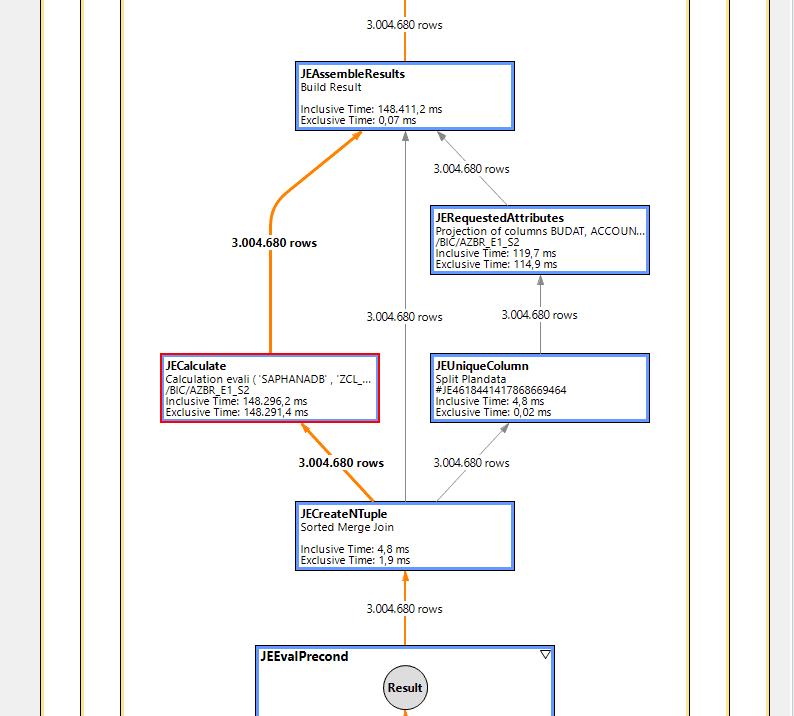
PlanViz of the query with UDF
It is clearly visible that the same execution plan is broadly chosen. But the runtime of the one, red-marked JECalculate node contains the entire runtime for the UDF call. This should at least be parallelised.
Why is that? Do I have a misconception in my example? Can I still optimize this? Or are the UDFs just so slow. While researching forums, I have seen that I am not alone with my problems. There are also several ways to slow down the system with unfavorable functions. (((Examplesof unfavorable UDF function in memory problem)) ((Multiple call of scalar UDFs with multiple return parameters)) ((No parallel execution of multiple UDFs))
In any case, there is still great potential. At least for simple expressions without querying other DB tables.
I realise that there are also complex requirements that cannot be reduced to a single expression. But then at least parallel processing would be desirable.
Update 10/8/2020:
Update of 8.10.2020: I still have a bit of a discussion about performance optimization today. I also stumbled across the HINTS. The HINT (INLINE) is supposed to trigger exactly the desired behavior: Optimization should be done globally. But unfortunately there is nothing in the documentation about functions. Everything refers to procedures. And this is also in line with my observation: the hint brings absolutely no change. It remains slow.
do begin
select budat,
"ZCL_CALDAY=>TO_CALMONTH"(BUDAT),
account,
amount,
curr
from "/BIC/AZBR_E1_S2"
WITH HINT(INLINE);
end;
Addendum, 11/10/2020:
Lars Breddemann has taken up the topic in his blog and has made his own measurements in this area. Some of these measurements I can relate to, but others I cannot. I suspect the differences are related to the version of the HANA database being used. All my measurements have been done on a BW/4HANA 2.0 SPS0 system with the HANA 2.00.036.00.1547699771. Lars probably used a newer version of HANA. Here are my comments on individual points:
The keyword DETERMINISTIC
The worse performance of DETERMINISTIC functions was confirmed by Lars. He recommends not using the DETERMINISTIC keyword, since it almost always leads to a non-optimal execution plan.
This also improves performance for me, but the scalar UDF still remains slower by a factor of 10. Here are the two implementation plans for it:
Without scalar UDF
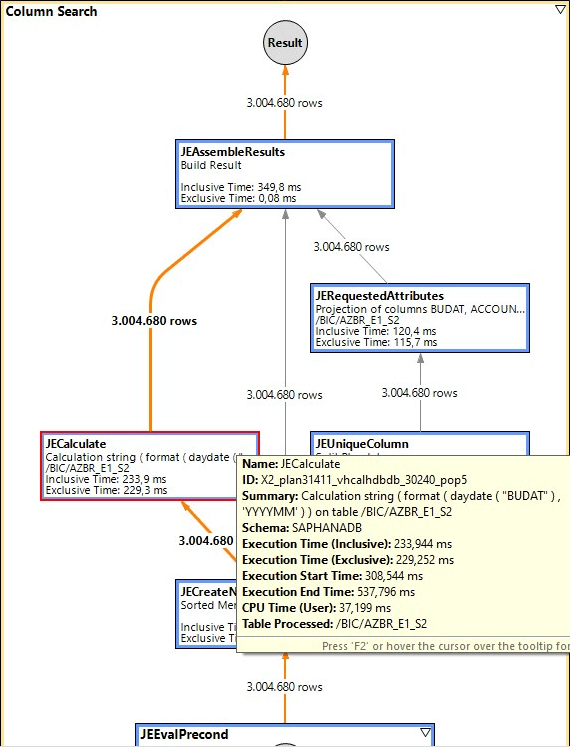
With scalar UDF
For 3million records, that's about 0.35 seconds vs. 3.7 seconds. The difference remains too great.
Memory consumption
I also can't confirm Lars' observation that memory consumption is significantly lower when using a scalar UDF. For me, the memory consumption is significantly larger with the scalar UDF:
532.4MBytes vs. 31.8 GBytes
When using TOP 500:
906.6 KBytes vs. 7.2 MBytes
The Engines
Another difference is the engines used. In Lars' case, EXPLAIN shows that both Row and Column engines are used. For me, only the column engine is involved.
On my system state HANA 2.0 SP03 the performance of scalar UDFs is already much better after omitting DETERMINISTIC. However, it is still a far cry from using the expressions directly in the field list of a query. Since Lars has different observations on some points, there are obviously also dimensions that we have not considered so far. Probably the HANA version plays a big role in this.
Interim balance
On SAP HANA Cloud
Since I don't have HANA 2.0 SP04 or SP05 available, I moved to SAP HANA Cloud for my next measurements. In the process, I initially noticed considerably shorter runtimes. However, since it's a completely different hardware, I can't make any valid statements about how much of it is the HANA version.
But what strikes me about the execution plans is that the system optimizes much more cleverly here. The queries used above do not process all 3M records, as this is not necessary for the output of 1000 records in the console. ;-)
DISTINCT
If you perform the SELECT query with DISTINCT, then the system is forced to process the entire data set. However, this leads to additional work in a JEPreAggregat node, which then takes care of the GROUP BY. To keep this effort from dominating, I only looked at the one column:
select distinct
-- to_calmonth(budat) as calmonth
TO_VARCHAR(TO_DATE(budat), 'YYYYMM') as calmonth
from ztr_data;
The difference between the scalar UDF and the direct use of the expressions seems to melt more and more.
I will provide more detailed measurements in this article soon.