GUID und UUID in SAP HANA
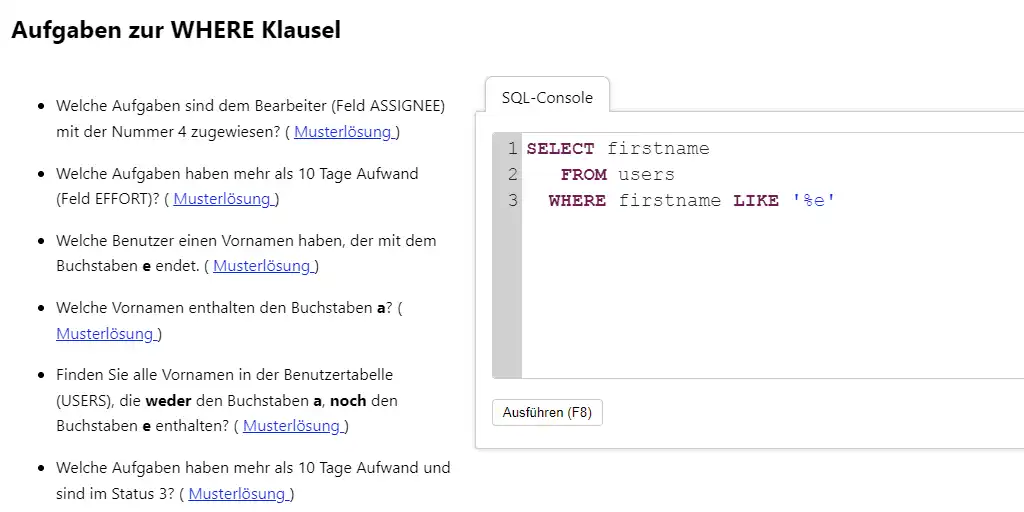
Es begegnen einem häufig GUID und UUID in [SAP HANA](/blog/category/sap-hana/) und im S/4HANA als Schlüsselfelder. Solange diese nicht interpretiert bzw. konvertiert werden müssen, ist das für die SAP HANA kein Problem. Voraussetzung dafür ist ein einheitlicher Datentyp. Es gibt aber unterschiedlich
Weiterlesen