Beim Laden von Daten aus Quellsystemen gibt es im SAP BW Anforderungen, die sich auf Feldebene häufig wiederholen. Dazu gehören vor allem Logiken zum Bereinigen und Aufbereiten der Daten, wie zum Beispiel:
- Hinzufügen und entfernen von führende Nullen
- Fallunterscheidungen
- Entfernen von Leerzeichen am Anfang oder Ende
- Konvertierung in Großbuchstaben
- Ableiten eines Feldes aus einem anderen mit Substrings nach festem Muster, z.B. COAREA ==> COUNTRY
- Ableiten von Zeitmerkmalen
Das folgende Listing zeigt ein paar Beispiele im Quellcode:
outTab = SELECT TO_VARCHAR(TO_DATE(calday), 'YYYYMM') AS calmonth,
"/BIC/SRCSYS",
...
"/BIC/CURTYP",
LEFT("/BIC/COAREA", 2) AS "/BIC/COUNTRY",
SUBSTRING("/BIC/BI_PROFCT", 9, 2) as "/BIC/PCACCID",
CASE SUBSTRING("/BIC/PROFCT", 8, 3)
when '643' then '1'
when '655' then '1'
when '641' then '2'
when '651' then '2'
when '643' then '3'
when '655' then '3'
else ''
end as "/BIC/PRBY',
...
FROM :intab;
Allen diesen Anforderung ist gemein, dass sie
- sich in SQLScript mit den vorhandenen SQL-Funktionen einfach implementieren lassen
- sich oft wiederholen
- von der SAP HANA sehr schnell ausgeführt werden können, solange sie direkt in der Transformationsroutinen implementiert sind.
DRY - Don't Repeat Yourself
Das bekannte DRY Prinzip sollte hier eigentlich zum Tragen kommen. Also das man den Quelltext nicht ständig wiederholt. In der Feldliste bieten sich hierfür die skalaren, Benutzerdefinierten Funktionen (UDF) an. Diese waren bis vor Kurzem kein Thema für die Transformationsroutinen im BW, weil diese erst seit AS ABAP Release 753 mit dem AMDP Framework erstellt werden können1. Aber genau für die genannten Anforderungen wären skalare UDFs eigentlich ideal. Damit kann man eine einheitliche Implementierung gewährleisten. Und man kommt im Quelltext von einer technischen Beschreibung der Ausdrücke zu einer fachlichen Sicht:
outTab = SELECT "ZCL_CALDAY=>TO_CALMONTH"(calday) AS calday
"/BIC/SRCSYS",
...
"/BIC/CURTYP",
"ZCL_COAREA=>TO_COUNTRY"("/BIC/COAREA") AS "/BIC/COUNTRY",
"ZCL_PROFCT=>TO_PCACCID"(/BIC/PROFCT") as "/BIC/PCACCID",
"ZCL_PROFCT=>TO_PRBY"(/BIC/PROFCT") as "/BIC/PRBY',
...
FROM :intab;
Die ausgelagerten Funktionen sehen sehr viel eleganter aus. Und auch unter dem Aspekt der Wartung sind sie haushoch überlegen. Wenn beispielsweise ein weiteres Profitcenter in der Liste auftaucht, dann gibt es genau eine Funktion, die man anpassen muss. Am Beispiel von ZCL_PROFCT=>TO_PRBY zeige ich eine solche skalare AMDP Funktion:
CLASS zcl_profct DEFINITION
PUBLIC
FINAL
CREATE PUBLIC .
PUBLIC SECTION.
INTERFACES if_amdp_marker_hdb.
METHODS to_prby IMPORTING VALUE(iv_profct) TYPE char10
RETURNING VALUE(rv_prby) TYPE char1.
ENDCLASS.
CLASS zcl_profct IMPLEMENTATION.
METHOD to_prby BY DATABASE FUNCTION FOR HDB LANGUAGE SQLSCRIPT OPTIONS DETERMINISTIC READ-ONLY.
rv_prby = case SUBSTRING(:iv_profct, 8, 3)
WHEN '643' then '1'
WHEN '655' then '1'
WHEN '641' then '2'
WHEN '651' then '2'
WHEN '643' then '3'
WHEN '655' then '3'
ELSE ''
END ;
ENDMETHOD.
ENDCLASS.
An dem Beispiel sieht man gut, dass die Funktion nur eine einfache "Hülle" für einen CASE-Ausdruck ist. Die Auslagerung in die ABAP Welt ermöglicht übrigens auch, ganz einfach UnitTests für die Funktionen zu schreiben. Da die Funktionen in der Datenbank erst beim ersten Aufruf aus dem ABAP generiert werden, bieten sich UnitTests auch dafür an.2
Elegant, aber langsam
So elegant die Auslagerung von Logik in UDFs auch ist, für große Datenmengen ist das Konzept leider nicht zu gebrauchen. Denn die UDFs beeinflussen die Laufzeit erheblich. Das möchte ich an einem anderen Ausdruck aus dem obigen Beispiel zeigen:
TO_VARCHAR(TO_DATE(calday), 'YYYYMM')
Dieser einfache Ausdruck wandelt ein ABAP DATS Wert in ein SQLScript Datum, dass dann wiederum in eine Zeichenkette im Format YYYYMM ausgegeben wird. Dieses entspricht dem Format des beliebten InfoObject CALMONTH.
Beispiel: 20200928 ==> 202009
Dafür legen ich nach dem obigen Muster eine AMDP UDF an:
METHOD to_calmonth BY DATABASE FUNCTION FOR HDB LANGUAGE SQLSCRIPT OPTIONS DETERMINISTIC READ-ONLY.
rv_result = TO_VARCHAR(TO_DATE(:iv_calday), 'YYYYMM');
ENDMETHOD.
Ich habe zwei Abfragen in der SQL-Konsole auf eine kleine BW-Tabelle mit ca. 3 Mio Einträgen gemacht: Einmal direkt mit dem Ausdruck und einmal mit dem Funktionsaufruf.
Ohne UDF
do begin
select budat,
TO_VARCHAR(TO_DATE(budat), 'YYYYMM'),
account,
amount,
curr
from "/BIC/AZBR_E1_S2";
end;
Konsole
Statement 'do begin select budat, TO_VARCHAR(TO_DATE(budat), 'YYYYMM'), account, amount, curr from ...' successfully executed in 501 ms 237 µs (server processing time: 801 ms 664 µs) Fetched 1000 row(s) in 102 ms 468 µs (server processing time: 0 ms 677 µs) Result limited to 1000 row(s) due to value configured in the Preferences
Mit UDF
do begin
select budat,
"ZCL_CALDAY=>TO_CALMONTH"(BUDAT),
account,
amount,
curr
from "/BIC/AZBR_E1_S2";
end;
Konsole
Statement 'do begin select budat, "ZCL_CALDAY=>TO_CALMONTH"(BUDAT),
account, amount, curr from ...'
successfully executed in 2:09.418 minutes (server processing time:
4:18.632 minutes)
Fetched 1000 row(s) in 103 ms 144 µs (server processing time:
0 ms 675 µs)
Result limited to 1000 row(s) due to value configured in the
Preferences
Die Laufzeiten sind dermaßen unterschiedlich, dass man eigentlich von einem Bug ausgehen muss. Denn die Komplexität bei dem Besipiel ist minimal. Mit weniger Komplexität brauche ich auch keine UDF mehr. Was ich erstaunlich finde:
- Tatsächlich stehen in der Tabelle nur 365 unterschiedliche Werte von BUDAT drin. Damit hat das System die Information: Bei gleicher Eingabe sollte auch das gleiche Ergebnis geliefert werden. Siehe SAP Dokumentation zur CREATE FUNCTION Anweisung. Damit sollte sie maximal 365 Mal ausgeführt werden und danach aus dem Puffer gelesen werden, oder?
- Ich hätte auch erwartet, dass eigentlich nur das Wörterbuch der Spalte konvertiert wird, also jeder Wert genau ein Mal.
- Wenn man mit einem primitiven Texteditor mit einfachem Suchen / Ersetzen den Funktionsaufruf durch den Funktionsinhalt ausgetauscht hätte, ist man über 100 x schneller. Das sollte der Optimizer einer SAP HANA 7 Jahre3 nach der Einführung skalarer UDFs doch hinbekommen, oder?
Um das ganze vollständig zu dokumentieren, habe ich auch noch die Analyse mit PlanViz gemacht.
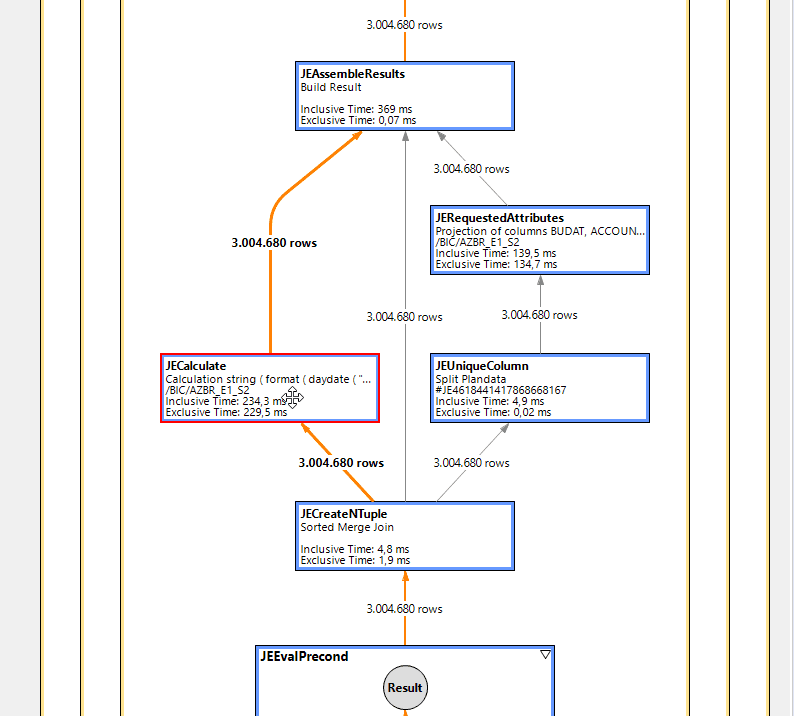
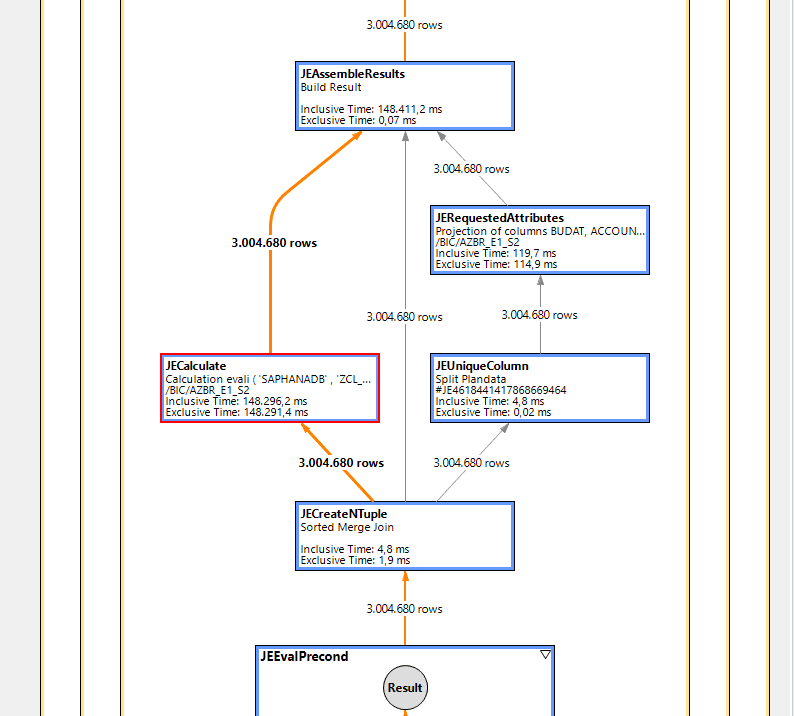
Es ist gut sichtbar, dass im Großen und Ganzen der gleiche Ausführungsplan gewählt wird. Aber die Laufzeit des einen, rot markierten JECalculate Knoten enthält die gesamte Laufzeit für die UDF Aufruf. Das müsste sich doch zumindest parallelisieren lassen.
Warum ist das so? Habe ich einen Denkfehler in meinem Beispiel? Kann ich das noch optimieren? Oder sind die UDFs einfach so langsam. Bei der Recherche in Foren habe ich gesehen, dass ich mit meinen Problemen nicht alleine bin. Es gibt auch mehrere Möglichkeiten, mit ungünstigen Funktionen das System auszubremsen.4[^,] 5[^,] 6
Es besteht auf jeden Fall noch großes Potenzial. Zumindest für einfach Ausdrücke ohne Abfragen auf andere DB-Tabellen.
Mir ist klar, dass es auch komplexe Anforderungen gibt, die sich nicht auf einen einzigen Ausdruck reduzieren lassen. Aber dann wäre zumindest eine parallele Verarbeitung wünschenswert.
Update vom 8.10.2020:
Ich habe mich heute noch etwas mit dem Thema Performanceoptimierung beschäftigt. Dabei bin ich auch über die HINTS gestolpert. Mit dem HINT(INLINE) soll eigentlich genau das gewünschte Verhalten ausgelöst werden: Die Optimierung sollte global erfolgen. Aber leider steht in der Dokumentation nichts über Funktionen. Alles bezieht sich auf Prozeduren. Und das entspricht auch meiner Beobachtung: Der Hint bringt absolut keine eränderung . Es bleibt langsam.
do begin
select budat,
"ZCL_CALDAY=>TO_CALMONTH"(BUDAT),
account,
amount,
curr
from "/BIC/AZBR_E1_S2"
WITH HINT(INLINE);
end;
Nachtrag vom 10.11.2020:
Lars Breddemann hat in seinem Blog das Thema aufgegriffen und selber in diesem Bereich Messungen angestellt. Manche dieser Messungen kann ich nachvollziehen, andere aber nicht. Ich vermute, dass die Unterschiede mit der Version der verwendeten HANA Datenbank zusammenhängen. Alle meine Messungen sind auf einem BW/4HANA 2.0 SPS0 System mit der HANA 2.00.036.00.1547699771 durchgeführt worden. Vermutlich hat Lars eine neuer HANA Version verwendet. Hier meine Anmerkungen zu einzelnen Punkten:
Das Schlüsselwort DETERMINISTIC
Die schlechtere Performance von DETERMINISTIC Funktionen wurde von Lars bestätigt. Er empfiehlt, das Schlüsselwort DETERMINISTIC nicht zu verwenden, da es quasi immer zu einem nicht-optimalen Ausführungsplan führt.
Das bringt auch bei mir auch eine Verbesserung der Performance, aber die skalare UDF bleibt immernoch um den Faktor 10 langsamer. Hier die beiden Ausführungspläne dazu:
Ohne skalarer UDF
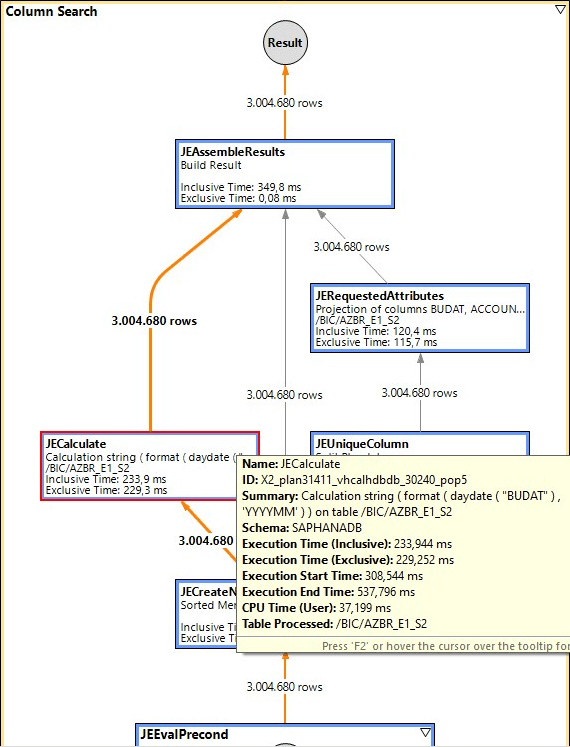
Mit skalarer UDF
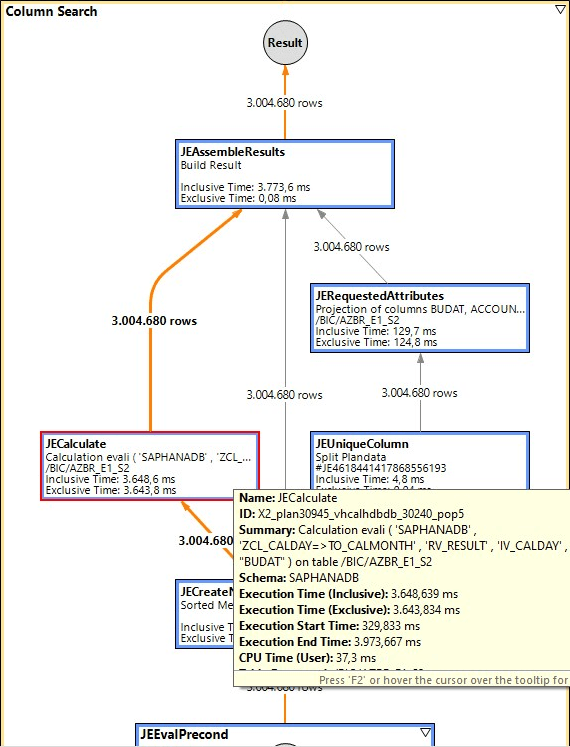
Für 3Mio Datensätze sind das ca. 0,35 Sekunden vs. 3,7 Sekunden. Der Unterschied bleibt zu groß.
Speicherverbrauch
Auch die Beobachtung von Lars, dass der Speicherverbrauch bei der Verwendung einer skalaren UDF erheblich geringer ist, kann ich nicht bestätigen. Bei mir ist der Speicherverbrauch bei der skalaren UDF erheblich größer:
532,4MBytes vs. 31,8 GBytes
Bei Verwendung von TOP 500:
906,6 KBytes vs. 7,2 MBytes
Die Engines
Ein weiterer Unterschied sind die verwendeten Engines. Bei Lars zeigt EXPLAIN, dass sowohl Row- als auch Column-Engine verwendet werden. Bei mir ist nur die Column-Engine involviert.
Auf meinem Systemstand HANA 2.0 SP03 ist die Performance von skalaren UDFs nach dem Weglassen von DETERMINISTIC schon deutlich besser. Sie ist aber immer noch weit entfernt von dem direkten Verwenden der Ausdrücke in der Feldliste einer Abfrage. Da Lars in einigen Punkten andere Beobachtungen hat, gibt es offenbar auch noch Dimensionen, die wir bislang nicht berücksichtigt haben. Wahrscheinlich spielt die HANA Version hierbei eine große Rolle.
Zwischenbilanz
Auf SAP HANA Cloud
Da ich keine HANA 2.0 SP04 oder SP05 zur Verfügung habe, bin ich in die SAP HANA Cloud für meine nächsten Messungen gezogen. Dabei habe ich zunächst erheblich kürzere Laufzeiten feststellen können. Da es sich aber um eine völlig unterschiedliche Hardware handelt, kann ich keine validen Aussagen darüber treffen, wie groß der Anteil an der HANA Version daran ist.
Was mir aber bei den Ausführungsplänen auffällt: Das System optimiert hier wesentlich cleverer. Bei den oben verwendeten Abfragen werden nicht alle 3Mio Datensätze verarbeitet, da das für die Ausgabe von 1000 Datensätzen in der Konsole nicht notwendig ist. ;-)
DISTINCT
Wenn man die SELECT Abfrage mit DISTINCT durch führt, dann wird das System dann doch dazu gezwungen, die gesamte Datenmenge zu verarbeiten. Das führt aber zu zusätzlichem Aufwand in einem JEPreAggregat Knoten, der sich dann um das GROUP BY kümmert. Damit dieser Aufwand nicht dominiert, habe ich nur die eine Spalte betrachtet:
select distinct
-- to_calmonth(budat) as calmonth
TO_VARCHAR(TO_DATE(budat), 'YYYYMM') as calmonth
from ztr_data;
Der Unterschied zwischen der skalaren UDF und der direkten Verwendung der Ausdrücke scheint immer mehr zu schmelzen.
Genauere Messungen werde ich demnächst in diesem Artikel nachreichen.
Footnotes
-
Ich verwende bewusst keine von BW-InfoObjects generierten Datenelemente, damit die Abhängigkeit so gering wie möglich ist. ↩
-
Scalar User Defined Functions in SAP HANA - Der erste Blog Beitrag zu dem Thema von Rich Heilmann von 2013 ↩
-
Mehrfacher Aufruf skalarer UDFs mit mehreren Rückgabeparametern ↩