


Mit dem BW/4HANA 2.0 habe ich beobachtet, dass die Paketgröße der DTPs vom System dynamisch vorgeschlagen wird. In der Abbildung 1 sieht man beispielsweise eine vorgeschlagene Größe von 1.311.000 Datensätzen. Damit wagt sich das System in eine Größenordnung vor, die aus eigener praktischer Erfahrung besser ist, als der ehemalige fixe Standardwert von 100.000 Zeilen.
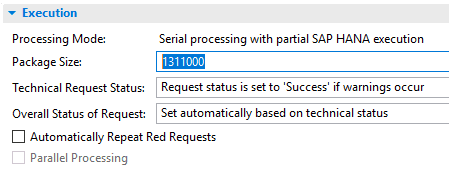
Abbildung 1: Vorschlagswert für die DTP Paketgrösse
In diesem Blogpost habe ich ein paar nützliche Informationen in Bezug auf die DTP Paketgröße zusammengetragen und diese um eine eigenes Beispiel mit einer Messreihe ergänzt.
Tatsächliche Größe der Pakete bei HANA Ausführung
Bei der HANA Ausführung von DTPs sehen wir im Monitor für jedes Paket immer nur genau eine Anzahl von Datensätzen. Bei ABAP Ausführung wurde hier für jeden Teilschritt eine Anzahl angegeben: Extraktion, Transformation, Einfügen, etc. . Diese Teilschritte lassen sich aber bei HANA Ausführung nicht mehr unterscheiden. Alle Logik aus Extraktion, Transformationsregeln, Routinen und das ggf. über mehrere Ebenen, wird in ein CalculationSzenario eingebunden, aus dem dann später gelesen wird. Und dieses Szenario wird als Ganzes optimiert. Damit haben wir keine Einzelwerte mehr für die jeweiligen Schritte. Und das erklärt auch, warum die Anzahl von Datensätzen im Monitor erst nach der Verarbeitung eines ganzen Paketes angezeigt wird, und nicht wie früher jeweils Schritt für Schritt.
Wieviele Daten tatsächlich auf einmal verarbeitet werden, hängt von mehreren Parametern ab. Die Paketgröße im DTP gibt die Anzahl der Datensätze in der Quelle an. Normalerweise werden dann N Pakete dieser Größe gebildet, das letzte der Pakete wird meistens nicht ganzu voll.
Wenn die Daten requestweise abgeholt werden, dann wird dieses Verfahren für jeden einzelnen Request wiederholt. D.h. für jeden Request gibt es ein Paket, das nicht die volle Paketgröße hat.
Wenn eine semantische Partitionierung eingestellt ist, dann werden die Daten nicht requestweise abgeholt. Statt dessen werden in jedes Paket so viele Partitionen eingefügt, bis die Paketgröße überschritten wird. Bei ungünstiger Wahl der Partitionierungskriterien kann es sein, dass so enorm große bzw. ungleichmäßige Pakete anfallen.
Die tatsächliche Paketgröße wird aber auch durch die Transformationsroutinen beeinflusst. Wenn beispielsweise ein Filter in Form einer WHERE-Klausel auf die INTAB in einer SQLScript Routine angewendet wird, dann wird die Anzahl der Datensätze in dem Paket entsprechend reduziert. Diese Bedingung wird bis in die Extraktion der Daten runtergedrückt. Da die Paketbildung aber vor der Verarbeitung der einzelnen Pakete stattfindet, werden die Pakete effektiv durch das Filterkriterium verkleinert.
Umgekehrt kann es auch vorkommen, dass die tatsächliche Paketgröße durch die Logik in den Routinen erhöht wird. Das ist zum Beispiel der Fall, wenn sich Daten durch einen Join ausmultiplizieren oder eine Transponierung von Daten von einem Kennzahlenmodell in ein entsprechendes Merkmalsmodell stattfindet.
Wichtig für eine gute Performance ist die tatsächliche Anzahl von Datensätzen.
Optimale Paketgröße bei HANA Ausführung
Eine ungünstige Paketgröße reduziert die Laufzeit. Bei der HANA Ausführung können die Pakete erheblich größer sein, als bei ABAP Ausführung. Eine Größenordnung von 1.000.000 Datensätze ist in den meisten Fällen ein guter Startwert, wenn man keine Vorschläge vom System bekommt. Wichtig ist, das es sich hierbei um die tatsächliche Anzahl der Datensätze handelt. Wenn also Ihre Routinen 90% der Datensätze ausfiltern, sollten Sie dieses in der Paketgröße der DTPs berücksichtigen.
Wenn die Pakete zu groß werden, dann kann es vorkommen, dass die Anzahl der Parallelen Prozesse nicht ausgenutzt wird. Ein Beispiel dafür sehen sie im folgenden Beispiel.
Die optimale Paketgröße kann man nur durch Tests ermitteln. Diese sollten auf dem Produktivsystem mit echten Daten durchgeführt werden.
Beispiel für ein DTP mit Verarbeitungslogik
Im Folgenden zeige ich die Laufzeiten für einen DTP, der eine Transformation beinhaltet, die aus einem Datensatz durch Transponieren jeweils 16 Datensätze macht. Dies ist erforderlich, um die PCA-Plandaten aus dem Kennzahlenmodell ein Merkmalsmodell umzuwandeln, in der jeder Datensatz für eine Periode steht. In dem Beispiel sind in der Quelle 1.994.590 Datensätze, woraus durch die Routine 31.913.440 Datensätze im Ziel werden.
| Paketgröße im DTP | Tatsächliche Anzahl Datensätze | Laufzeit in Sekunden |
| 10.000 | 160.000 | 243 |
| 62.500 | 1.000.000 | 155 |
| 100.000 | 1.600.000 | 138 |
| 1.000.000 | 16.000.000 | 258 |
Tabelle 1: Laufzeit in Abhängigkeit von der Paketgröse
Der Vorschlagswert des BW/4HANA Systems für die DTP Größe ist 1.000.000 Datensätze. Durch die Vervielfältigung der Datensätze ist das aber natürlich nicht mehr optimal. Wenn wir statt dessen eine Paketgröße wählen, so dass die tatsächlich Anzahl an Datensätzen ca. 1.Mio. entspricht, dann ist die Laufzeit erheblich besser. In unserem Beispiel ist das Optimum bei 1.6Mio. tatsächlichen Datensätzen.
Auswirkung der Anzahl der Workprozesse bei HANA Ausführung
Neben der Paketgrösse hat natürlich auch die Anzahl der Workprozesse einen Einfluss auf die Gesamtlaufzeit für einen DTP. Allerdings ist die Wirkung von einer Verdoppelung der Workprozesse bei weitem nicht so groß, wie man es naiv erwarten würde:
Für das obige Beispiel habe ich die Anzahl der Workprozesse von 3 auf 6 hochsetzt. Dadurch verkürzt sich die Laufzeit von 138 Sekunden nur um 14% auf 121 Sekunden.
Von der ABAP Ausführung kennen wir hier eine halbwegs lineare Abhängigkeit von Laufzeit und Anzahl der Workprozesse. Wobei man beim Ausführen der Prozessketten immer darauf achten muss, dass die Gesamtzahl der Hintergrundprozesse (Typ BTC) auch ausreicht.
Zusammenfassung
Die Paketgröße ist ein wichtiger Parameter zur Optimierung der DTP Laufzeit. Mit der HANA Ausführung können wir jetzt grundsätzlich größere Pakete wählen. Der Vorschlagwert von BW/4HANA 2.0 muss manchmal angepasst werden, insbesondere wenn die Transformationslogik die tatsächliche Anzahl der Datensätze verändert. Hier hilft oft nur ausprobieren.











