In diesem Artikel will ich die unterschiedlichen Möglichkeiten zur Speicherung von Hierarchien in SAP HANA ((Natürlich sind das alles allgemeine Ansätze, die in jeder Datenbank möglich sind. Bei der Bewertung am Ende des Artikels gehe ich aber kurz auf die Hierarchiefunktionen der SAP HANA ein.)) aufzeigen. Mit den üblichen Ansätzen zum Speichern von hierarchischer Daten in einer Datenbank wie dem Parent-Child Datenmodell oder dem "Flachklopfen" in einer Tabelle kann man die Hierarchiefunktionen der SAP HANA nutzen. Diese erlauben einen komfortablen (aber teilweise etwas trägen) Zugang zu einer Reihe sinnvoller Algorithmen. Wenn man den performanten Zugriff aber selber gestalten will, dann zeigt dieser Artikel ein paar alternative Ansätze zum Speichern der hierarchischen Daten.
Die Verarbeitung dieser Datenmodelle für Hierarchien in SAP HANA bzw. SQLScript werde ich in einem späteren Artikel eingehen.
Begriffe für Hierarchien
Balancierte und unbalancierte Hierarchien
Unter einer balancierten Hierarchie versteht man eine Anordnung, bei der jede Ebene die feste Bedeutung hat. Das können beispielsweise Adressdaten sein. Diese kann man sich als Hierarchie mit unterschiedlichen Ebenen vorstellen:
-
- Ebene: Land (Staat)
-
- Ebene: Bundesland
-
- Ebene: Gemeinde
-
- Ebene: Straße
-
- Ebene: Hausnummer
Das Gegenteil ist entsprechend eine unbalancierte Hierarchie. Hier können einzelne Zweige unterschiedlich viele Ebenen haben. Und die Bedeutung einer Ebene ist nicht festgelegt. Typische Beispiele sind Verzeichnisstrukturen auf dem PC oder das ein Organigramm eines Konzerns.
Bezeichnungen von Knoten
Die einzelnen Elemente einer Hierarchie bezeichnen wir als Knoten. Entsprechen Ihrer Eigenschaften unterscheiden wir die folgenden Arten von Knoten:
- Wurzelknoten – der oberste Knoten.
- Child-Knoten – Der Knoten unterhalb eines anderen Knoten
- Parent-Knoten – Der Knoten über einem anderen Knoten
- Geschwisterknoten – Ein Knoten mit dem selben Parent-Knoten
- Blattknoten – Ein Knoten ohne Child-Knoten
Datenmodelle zum Speichern von Hierarchien
Flachgeklopft: Die Ebenen balancierter Hierarchien als Spalten einer Tabelle
Die Ebenen einer balancierten Hierarchie werden als Spalten mit fester Semantik gespeichert. Beispielsweise die Adresse mit den folgenden Spalten:
- Land (Staat)
- Bundesland
- Gemeinde
- Straße
- Hausnummer
Das bedeutet, dass pro Blattknoten ein Datensatz gespeichert wird. Dadurch wird ein gewisses Maß an Redundanz in Kauf genommen. Beispielsweise liegt eine Gemeinde immer im gleichen Bundesland. Der Vorteil einer solchen Speicherung ist eine einfach Auswertung.
Ein Nachteil dieses Datenmodells ist, dass Daten auch falsch und widersprüchlich erfasst werden können. Wenn sich beispielsweise ein Sachbearbeiter beim Erfassen einer Adresse vertippt, dann kann eine Gemeinde Mannheim vielleicht einmal in Baden-Württemberg und einmal in Bayern liegen. Und wenn sich die Hierarchiestruktur verändert, was beim Beispiel der Adressen natürlich eher unwahrscheinlich ist, dann müssen alle betroffenen Datensätze angepasst werden.
Normalisiert: Jede Ebene in einer eigenen Tabelle
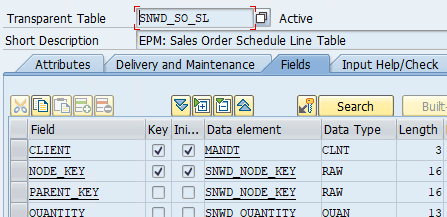
Die Alternative zur Flachen Tabelle ist es, für jede Hierarchieebene eine eigene Datenbanktabelle zu nutzen. Jede Ebene wird somit eindeutig der darüberliegenden Ebene zugeordnet. Ein Beispiel aus dem EPM bzw. SHINE Demo-Datenmodell der SAP sind beispielsweise die Sales Orders:
- SNWD_SO - EPM: Sales Order Header Table
- SNWD_SO_I - EPM: Sales Order Item Table
- SNWD_SO_SL - EPM: Sales Order Schedule Line Table
- SNWD_SO_I - EPM: Sales Order Item Table
Jeder Datensatz in den Tabellen hat eine GUID als technischen Schlüssel im Feld NODE_KEY. Die Verknüpfung mit der darüber liegenden Ebene erfolgt über das Feld PARENT_KEY
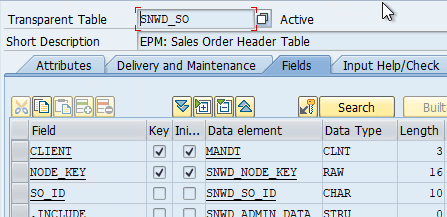
Kopfebene
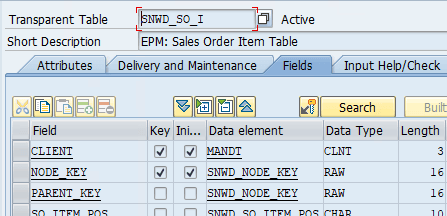
Positionsebene
Einteilungsebene
Speicherung als Parent-Child (Adjazenzliste)
Die Speicherung unbalancierter Hierarchien erfolgt meistens im Parent-Child Modell. Dabei wird für jede Ebene die Eltern-Ebene mit abgespeichert. Die Top-Knoten selber haben keinen Elternknoten. Eine Verallgemeinerung der Parent-Child Modells ist die Adjazenzliste, die zum Abspeichern eines beliebigen Graphen verwendet werden kann. Da eine Hierarchie in der Graphentheorie einem gerichteten Baum mit Wurzelknoten entspricht, lässt er sich ohne weiteres in diesem Format speichern. Der Unterschied zur Reinform einer "normalen" Adjazenzliste ist, dass ein Knoten nur einmal als Child vorkommt und häufig auch noch weitere Attribute in der Tabelle abspeichert.
Ein typisches Beispiel für Parent-Child Tabellen sind die Hierarchien im SAP BW. Diese werden in den generierten H-Tabellen der InfoObjects gespeichert werden. Die Hierarchietabelle des Profit-Center (InfoObject PROFIT_CTR) sieht beispielsweise so aus:
- HIEID - (Key) Schlüssel der Hierarchie
- OBJVERS - (Key) Objektversion (
- NODEID - (Key) Schlüssel des Knotens als Integer. Das ist in diesem Fall entweder ein
- IOBJNM - InfoObject: Der Datentyp des Knotens.
- NODENAME - Semantischer Schlüssel des Knotens
- TLEVEL - Ebene der Hierarchie
- LINK - Flag für Link-Knoten, die einen Verweis auf einen anderen Knoten darstellen
- PARENTID - Schlüssel (NODEID) des Eltern-Knotens
- CHILDID - Schlüssel (NODEID) des ersten Kind-Knotens, falls vorhanden
- NEXTID - Schlüssel (NODEID) des nächsten, also rechts davon befindlichen, Geschwisterknoten, falls vorhanden
- INTERVL - Intervall-Flag
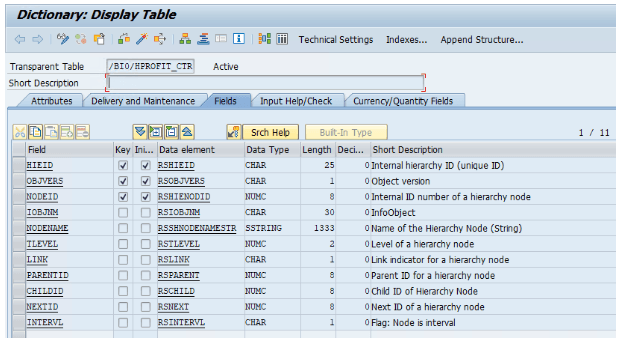
Hierarchietabelle /BI0/HPROFIT_CTR
Dieses Format geht über die übliche Parent-Child Hierarchien hinaus, da noch weitere Hierarchieinformationen gespeichert werden. TLEVEL, CHILDID und NEXTID müssen beim Laden von Hierarchien gefüllt sein. Leider ist das SAP BW sehr pingelig, was die Konsistenz dieser Informationen angeht.
Speicherung von Hierarchien in SAP HANA im Nested-Set Modell
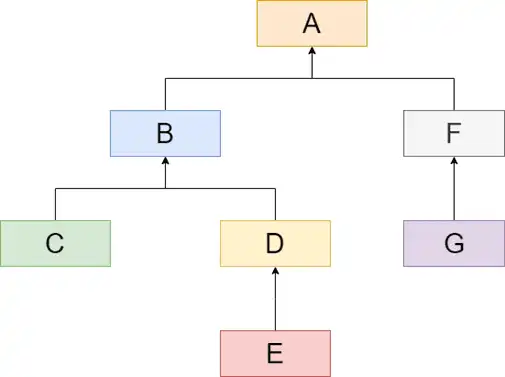
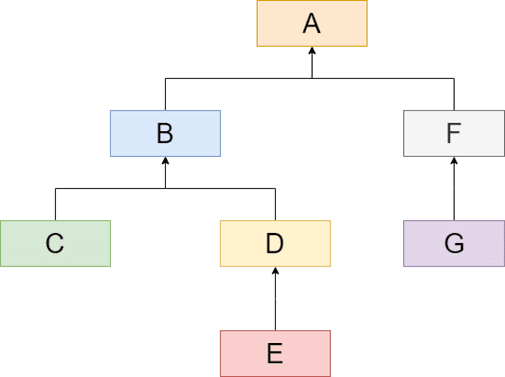
Das Nested-Sets (zu deutsch: Verschachtelte Mengen, im englischen auch modified preorder tree traversal oder MPTT genannt) Modell betrachtet einen Knoten in einer Hierarchie als die Menge aller Knoten darunter. Diese sind ebenfalls wieder Mengen.
In dem Beispiel rechts würde das also bedeuten:
- Die Menge A enthält die Mengen B, C, D, E, F und G
- Die Menge B enthält die Mengen C, D und E
- ... und so weiter
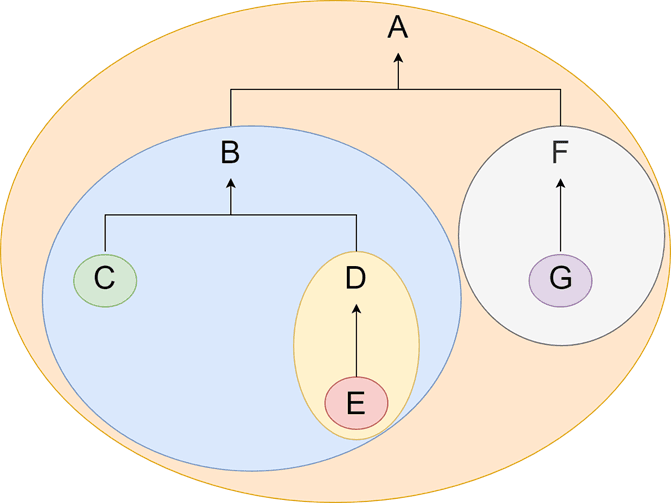
Ohne Weiteres kann man die Hierarchie auch als Mengendiagramm darstellen, wie man es aus der Schule kennt.
Und diese Mengen werden jetzt an einer Geraden entlang ausgerichtet. Diese Gerade hat für jede Menge einen Ein- und einen Austrittspunkt. Und diese Punkte werden jetzt von links nach rechts durchnummeriert:
- Die Menge A geht von 1 bis 14
- Die Menge B geht von 2 bis 9
- Die Menge C geht von 3 bis 4
- ... und so weiter
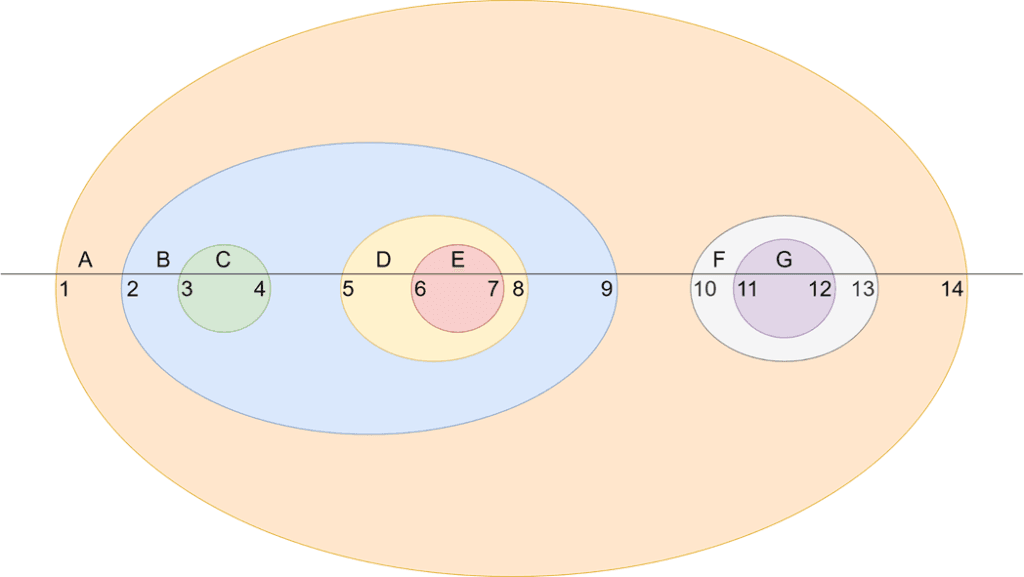
Die Tabelle sieht zunächst nicht sehr intuitiv aus. Um die Struktur zu erkennen muss man sich das als Mensch aufmalen. Aber diese Struktur hat auch große Stärken. Denn manche Fragestellungen können in diesem Format extrem schnell beantwortet werden.
Die Algorithmen zum Erzeugen und Verarbeiten von Nested-Set Hierarchien in SAP HANA werde ich in einem anderen Artikel beschreiben.
Speicherung als aufgelöste Hierarchie (Hierarchy Bridge Table)
Ein weiterer, wenig intuitiver Ansatz sind vollständig aufgelöste Hierarchien (Hierarchy Bridge Table) ((Leider ist der englische Begriff nicht intuitiv und man findet in der Literatur keinen deutschen Begriff. Deshalb nenne ich diese Form "Aufgelöste Hierarchien", da er den Sachverhalt meiner Meinung nach gut beschreibt.)). Diese materialisieren alle Verbindungen eines Knotens zu allen Unterknoten zusammen mit der Tiefe. Das Beispiel sehen Sie in der rechten Tabelle.
Dieses Format hat vor allem seine Stärke in der Filterung von Daten. Da alle Parent-Child Beziehungen über X-Ebenen aufgelöst sind, kann man sehr einfach per JOIN alle untergeordneten Knoten finden.
| NODE | CHILD | DEPTH |
|---|---|---|
| A | A | 0 |
| A | B | 1 |
| A | F | 1 |
| A | C | 2 |
| A | D | 2 |
| A | G | 2 |
| A | E | 3 |
| B | B | 0 |
| B | C | 1 |
| B | D | 1 |
| B | E | 2 |
| C | C | 0 |
| D | D | 0 |
| D | E | 1 |
| E | E | 0 |
| F | F | 0 |
| F | G | 1 |
| G | G | 0 |
Speicherung von Hierarchien als Pfad
Zu guter Letzt kann man Hierarchien in SAP HANA auch in ein Text-Feld als Pfad schreiben. So wie ein Verzeichnispfad oder in einer URL. Das sieht zunächst nicht besonders elegant aus, ist aber ein relativ flexibles Format.
Beim Suchen nach Unterknoten ist dieses Format sogar erstaunlich schnell.
Vergleich der Speicherung von Hierarchien in SAP HANA
Kriterien für den Vergleich
- Auch für unbalancierte Hierarchien - die ersten Datenmodelle können nur balancierte Hierarchien speichern. Es werden immer Blattknoten gespeichert.
- Keine Redundanten Daten - Manche Datenmodelle für das Speichern von Hierarchien in SAP HANA haben redundante Daten. Diese benötigen Speicherplatz und müssen bei Änderungen konsistent gehalten werden. Dadurch wird aber häufig eine bessere Performance erkauft.
- Aufwand bei der Erstellung - In Quellen liegt die Hierarchieinformation fast immer in flachen Tabellen oder als Parent-Child Modell vor. Entsprechend müssen die anderen Datenmodelle erst generiert werden. Der Aufwand hierfür ist sehr unterschiedlich.
- Aufwand für Änderungen - Für manche Anwendungsszenarien wird eine Hierarchie nie oder sehr selten geändert. Dann fallen die Kosten für die Änderung nicht groß ins Gewicht. In anderen Szenarien ändert sich die Hierarchie permanent. Entsprechend müssen diese Vorgänge schnell und einfach möglich sein.
- Performance - Die wichtigste Fragestellung im Reporting ist: Gib mir alle Kinder von Knoten X. Das wird sowohl beim Filtern auf Knoten als auch beim Aggregieren von Werten benötigt. Manche Datenmodelle sind auf diese eine Fragestellung hin optimiert.
- Unterstützung der HANA Hierarchiefunktionen - Die SAP HANA hat einige praktische SQL-Funktionen mit an Bord. Diese können in SQLScript oder in den CalculationViews genutzt werden. Dafür müssen die Hierarchien aber in einem geeigneten Format vorliegen.
| Daten | Erstellung | Aufwand für Änderungen | Performance | HANA | |||
|---|---|---|---|---|---|---|---|
| Auch für unbalancierte Hierarchien | Keine redundanten Daten | Aufwand bei der Erstellung | Knoten Einfügen | Zweig Umhängen | Alle Kinder eines Knotens | Hierarchiefunktionen und Hierarchien in CalcViews | |
| Flache Tabelle mit N Spalten | gering | Blattknoten: gering | hoch | schlecht | Ja | ||
| Normalisiert mit N Tabellen | X | gering | gering | gering | schlecht | Ja (über View) | |
| Parent-Child | X | X | gering | gering | gering | schlecht (rekursiv) | Ja |
| Nested-Set Modell | X | X | hoch | hoch | hoch | gut | Nein |
| Aufgelöste Hierarchie | X | hoch | hoch | hoch | gut | Nein | |
| Pfad als Text | X | gering | gering | hoch | gut | Nein |
Fazit
Die unterschiedlichen Formate zum Speichern von Hierarchien in SAP HANA bzw. in Datenbanken haben unterschiedliche Vor- und Nachteile. Solange es keine besonderen Anforderungen an die Berichtsperformance gibt, wird man wahrscheinlich immer zu den ersten drei klassischen Lösungen greifen. Aber es ist auch interessant, sich mit den anderen Datenmodellen auseinanderzusetzen. Gerade wenn es um große Hierarchien im Reporting geht, kann hier einiges optimiert werden.