Wachsen Daten eigentlich auf dem Feld?
Stellt Euch vor, wir würden über „Produkte“ so reden wie heute über „Datenprodukte“: „Wir haben da hinten ein Feld, da wächst irgendwas, wir ernten das einmal im Monat, kippen es in ein riesiges Silo, kleben ‚Data Lake‘ drauf – bitte bedienen Sie sich.“
Genau so funktionieren viele Datenplattformen heute: Batch-ETL, Pull-Modus, Fokus auf Finanz- und Controllingkennzahlen, am Ende eine Handvoll hübscher Dashboards mit KPIs.
Im besten Fall sind das ordentlich gewaschene Kartoffeln in großen Säcken am Straßenrand: formal korrekt, bilanziell relevant – aber weit weg von dem, was ein Kunde als „Produkt“ wahrnimmt.
Was ist überhaupt ein Produkt – und warum interessiert das Datenleute so wenig?
In der echten Welt gibt es einfache Produkte, die man im Supermarkt in die Hand nimmt, konfigurierbare Produkte wie Autos, hochkomplexe Maschinen mit Inbetriebnahme, Schulung und Wartungsvertrag. Es gibt digitale Produkte, die man in Sekunden herunterladen kann, Dienstleistungen und Subscriptions, bei denen man eher Zugang als einen Gegenstand kauft – und es gibt Anbieter, bei denen Produktion und Logistik selbst zum Produkt werden, wie Auftragsfertiger oder Fulfillment-Dienstleister.
Keines dieser Produkte entsteht, indem man einfach nur „Rohmaterial sammelt“.
Es braucht Einkauf, Zwischenprodukte, Fertigungslogistik, Qualitätssicherung, Verpackung, Vertriebskanäle und manchmal Zertifizierungen – vom Waffenschein bis zum Sicherheitsnachweis für Maschinen. In der Datenwelt dagegen nennen wir schon eine halbwegs dokumentierte Tabelle oder ein Dashboard „Datenprodukt“, obwohl echte Produktlogik (Zielgruppe, Lieferform, Servicelevel, Risiken, Reifegrad) meist nur am Rand vorkommt.
Wie sähe ein echter Data Store im Baumarkt-Stil aus?
Stellt Euch einen „Data Store“ wie einen Baumarkt vor.
Da gibt es Regale mit fertigen Paketen („Customer 360“, „Order History“, „Machine Health“), Zuschnittservice für Spezialformate, Beratung für komplexe Anwendungsfälle und Lieferung nach Hause – sprich: in dein System, deine App, dein Modell.
- Manche Kunden wollen rohe Kartoffeln (Low-Level-Events, Rohdatenströme).
- Andere wollen geschälte, vorgeschnittene Kartoffeln (harmonisierte Domain-Events oder standardisierte Entities).
- Wieder andere wünschen sich Kartoffelsuppe nach Omas Art (hochgradig kuratierte, fachlich geprüfte, direkt integrierbare Datenservices).
Und es gibt Kunden, die gar keine Kartoffeln mehr sehen wollen, sondern einen Lieferservice: „Hier ist mein Use Case – gib mir bitte die Daten so, dass sie in meinem Prozess funktionieren.“ Ein moderner Data Store müsste genau diese Bandbreite bedienen: von Rohstoff über Komponenten bis hin zu fertigen Produkten, inklusive Beratung, Service und klarer Beschriftung.
Warum Data Warehouse + KPIs einfach nicht reicht
Die bisherige Diskussion um Datenprodukte und Datenkataloge beginnt meistens im BI- oder Analytics-Team – und hört dort auch wieder auf.
Die „Daten“, die dort im Fokus stehen, sind oft verdichtete Finanzzahlen, KPIs und Berichte, die im Wochen‑ oder Monatsrhythmus aktualisiert werden – perfekt fürs Reporting, aber weitgehend nutzlos für Produktions- oder Serviceprozesse, die in Sekunden oder Millisekunden denken.
In der Produktion, im CRM oder in IoT-Szenarien reden wir über:
- Einzelobjekte wie Maschinen, Anlagen, Fahrzeuge, Kunden, Aufträge (Digital Twin).
- Echtzeit- und Near-Realtime-Anforderungen, bei denen „Batch über Nacht“ schlicht zu spät ist.
- Hohe Frequenzen und große Volumen, die Timeseries-Datenbanken, Streaming-Plattformen und spezialisierte Speicherformen erfordern, nicht nur klassische Relationen.
Wenn wir weiterhin so tun, als wären Data Warehouse, Data Lake und ein paar KPI-Dashboards das Zentrum des Datenuniversums, schneiden wir genau diese Welten ab – und wundern uns später, warum KI-Projekte scheitern oder Produktionsdaten nie dort ankommen, wo sie wirken könnten.
Wer produziert hier eigentlich was – und mit welcher Architektur?
In der Fabrik entstehen Daten nicht als Nebenprodukt eines Reports, sondern als integraler Bestandteil des Prozesses. Maschinen, Sensoren, Steuerungen, MES, ERP, CRM – sie alle sind Datenproduzenten und -konsumenten gleichzeitig.
Statt Punkt-zu-Punkt-Schnittstellen und individueller Spezialintegration setzen moderne Ansätze auf:
- Unified Namespace: ein zentraler, echtzeitfähiger Datenraum auf Basis von Message Brokern (z.B. MQTT, Kafka), in dem Systeme publizieren und subscriben, statt direkt miteinander zu sprechen.
- Data Broker: Komponenten, die Daten verteilen, standardisieren, absichern und kontextualisieren, bevor sie in Historian, Data Lake, Data Warehouse oder andere Systeme fließen.
- Spezialisierte Speicher: Timeseries-Datenbanken für Verlaufsdaten, Graphdatenbanken für Beziehungen zwischen Assets, Vektordatenbanken für semantische Suche und KI-Use-Cases.
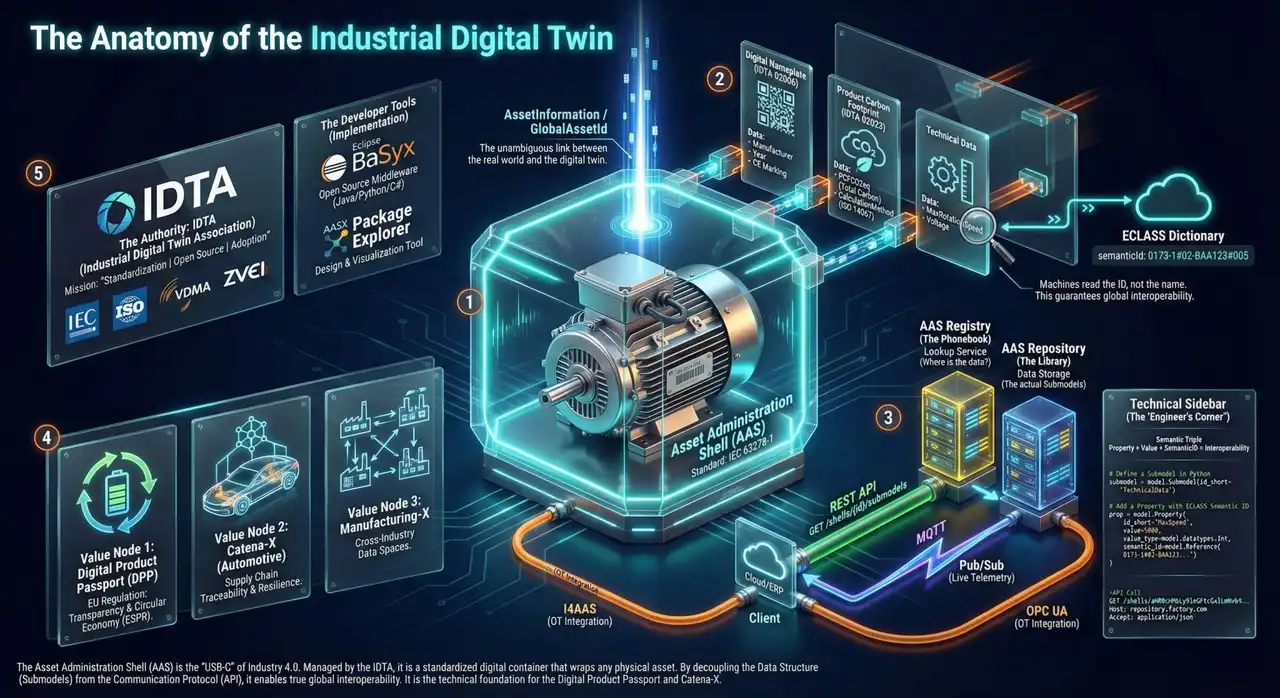
Und als semantisches Rückgrat kommt die Asset Administration Shell ins Spiel: Sie beschreibt Assets einheitlich, erlaubt Submodelle für Time Series, Carbon Footprint, digitale Typschilder und vieles mehr – kurz: Sie bringt Struktur und Bedeutung in einen ansonsten chaotischen Datenzoo.
Wenn wir von Datenprodukten in solchen Umgebungen sprechen, meinen wir nicht nur hübsch verpackte KPIs, sondern vollwertige, echtzeitfähige Informationsbausteine rund um konkrete Assets und Prozesse.
Wie schmeckt ein gutes Datenprodukt in Zeiten von KI?
Mit KI im Spiel reicht „irgendwie vorhandene Datenbasis“ nicht mehr – die Modelle sind nur so gut wie das, was wir ihnen zu essen geben.
Wir brauchen Daten, die:
- fachlich sinnvoll geschnitten sind (Entitäten, Events, Zustände statt beliebiger Tabellenfragmente),
- qualitätsgesichert und semantisch beschrieben sind (z.B. über AAS, Ontologien oder klar definierte Domänenmodelle),
- in passenden Formen vorliegen: relational, als Zeitreihen, als Graph, als Vektorraum – je nach Use Case.
Ein „Customer“-Datenprodukt kann etwa operative Prozesse unterstützen (Next Best Action in Echtzeit) und Analytical Use Cases (Segmentierung, Churn Prediction) – vorausgesetzt, es ist als echtes Produkt gedacht: mit Verantwortlichen, Lifecycle, SLA und standardisierten Schnittstellen.
KI braucht keine Kartoffelsäcke, sie braucht Rezepte, Zutatenlisten, definierte Portionen und manchmal sogar einen Lieferservice – kurze Latenz, klare Semantik, stabile Qualität.
Lasst uns weniger ernten – und mehr kochen
Was läuft also schief in der aktuellen Diskussion?
Wir starten beim Data Warehouse, nennen kuratierte Tabellen „Datenprodukte“ und erklären dann die Welt von dort aus – statt beim Kunden, beim Prozess oder beim Asset anzufangen.
Wir setzen Datenplattformen mit Lagerhäusern gleich, obwohl wir Fabriken brauchen, in denen Rohdaten, Zwischenprodukte und Endprodukte bewusst gestaltet werden – inklusive Logistik, Service und Feedbackschleifen.
Wie könnte es besser sein?
- Datenprodukte vom Kunden her denken: Wer braucht was, in welcher Form, mit welcher Aktualität und welchem Risiko?
- Datenplattformen als Wertschöpfungsketten verstehen: vom Shopfloor und den operativen Systemen über Unified Namespace, Broker und spezialisierte Speicher bis hin zu Analytics und KI.
- Semantik und Struktur ernst nehmen: Digital Twins, AAS, Domain-Modelle – nicht als Deko, sondern als Grundlage dafür, dass Datenprodukte stabil, wiederverwendbar und verständlich sind.
- Akzeptieren, dass Finanzdaten und KPIs wichtig sind – aber eben nur ein Teil der Geschichte. Produktionsdaten, Prozessdaten, Kundendaten in Echtzeit sind mindestens genauso wertvoll.
Wenn wir aufhören, Kartoffelsäcke am Straßenrand zu stapeln, und anfangen, in Rezepten, Menüs und Küchenprozessen zu denken, werden Datenprodukte plötzlich das, was sie eigentlich sein sollten: nutzbare, verlässliche und wertstiftende Angebote für ihre „Kunden“ – menschliche wie maschinelle.